20-40% of public goods funding is misallocated relative to outcome-maximizing benchmarks, representing trillions annually in foregone welfare gains. Budget processes respond to lobbying intensity and historical precedent rather than causal evidence of effectiveness.
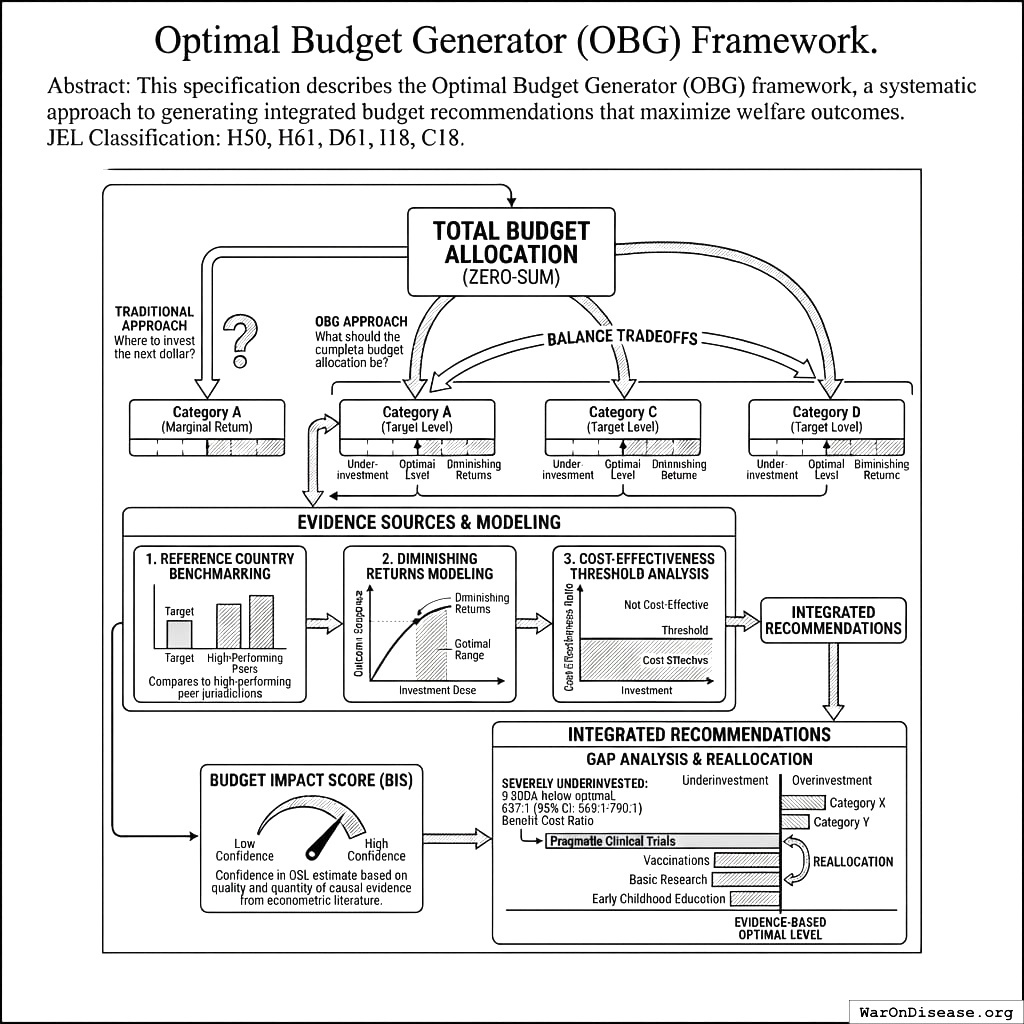
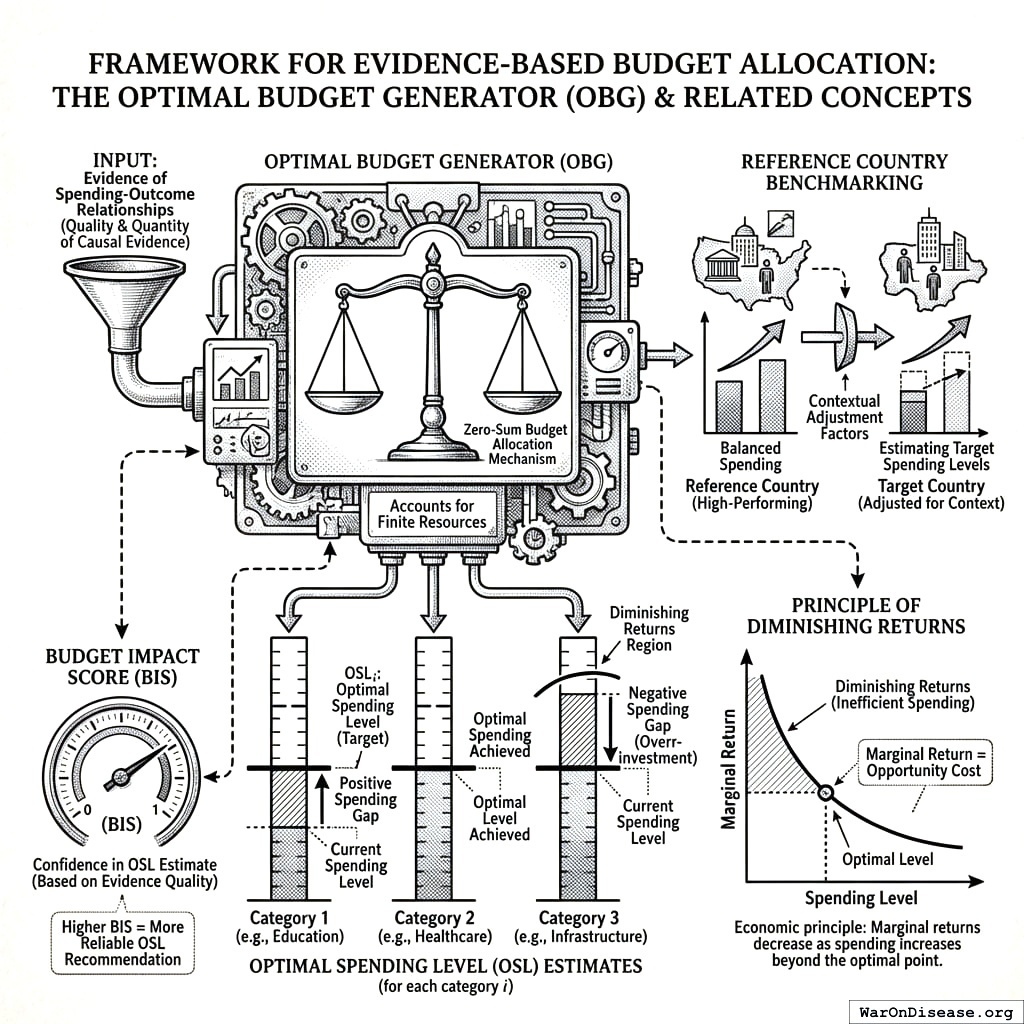
The Optimal Budget Generator (OBG) applies causal inference, diminishing returns modeling, and cost-effectiveness analysis to determine optimal public goods funding levels that maximize two terminal general-welfare metrics: real after-tax median income growth and median healthy life years. For each spending category, OBG estimates an Optimal Spending Level (OSL) identifying where marginal returns equal opportunity cost.
Your government decides how much to spend on each category the same way it has for decades: last year’s number, plus whatever the loudest lobbyist got added, minus whatever the latest crisis forced a cut on. This is called “the budget process.” It has no optimization function. It has no feedback loop. It has no measurable objective. It is, in the technical sense, not a process at all. It is an accident that repeats annually.
This specification describes the Optimal Budget Generator (OBG) framework, a systematic approach to generating integrated budget recommendations that maximize welfare as measured by two terminal general-welfare metrics: real after-tax median income growth and median healthy life years.
Three ways to figure out optimal spending combine to show the gap between what you spend and what you should spend. The gap is filled with lobbyists.
JEL Classification: H50, H61, D61, I18, C18
Unlike marginal-return frameworks that ask “where should we invest the next dollar?”, OBG asks “what should the complete budget allocation be?” Each category has a target level - too little means underinvestment, too much means diminishing returns. But unlike the Recommended Daily Allowance for nutrients (where you can meet all targets simultaneously), budget allocation is zero-sum: spending more on one category means less for others. OBG generates integrated recommendations that balance these tradeoffs.
The framework combines two evidence sources: (1) diminishing returns modeling from cross-country dose-response studies, and (2) cost-effectiveness threshold analysis from health economics. The Budget Impact Score (BIS) measures our confidence in each category’s OSL estimate based on the quality and quantity of causal evidence from the econometric literature.
The result is a gap analysis showing which categories are below evidence-based optimal levels, enabling systematic reallocation from overinvestment to underinvestment. Applied to the US federal budget, the framework identifies pragmatic clinical trials as the most severely underinvested category (9,900% below optimal with 637 (95% CI: 479-854):1 benefit-cost ratio), followed by vaccinations, outcome-funded R&D, and early childhood education.
A dashboard showing spending gaps by category, with clear recommendations:
Illustrative Example: US Federal Budget Gap Analysis
The following table demonstrates how OBG output would appear. OSL estimates for fully derived categories (pragmatic trials, vaccinations) come from the worked examples in Sections 6-7. Remaining OSL estimates use cross-country benchmarking.
Category
Current
OSL
Gap
Evidence
Income Effect
Health Effect
Action
Pragmatic clinical trials
$0.5B
$50B
+$49.5B
A (RCTs)
++
+++
Scale 100x
Vaccinations
$8B
$35B
+$27B
A (RCTs)
+
+++
Increase
Basic research
$45B
$90B
+$45B
B (spillovers)
++
++
Increase
Early childhood (0-5)
$50B
$70B
+$20B
A (RCTs)
+++
+
Increase
Military (discretionary)
$850B
$459B
-$391B
C (benchmarks)
−
−
Decrease
Agricultural subsidies
$25B
$0B
-$25B
A (welfare analysis)
−
−
Eliminate
Positive gaps indicate underinvestment; negative gaps indicate overinvestment. Income Effect: impact on real after-tax median income growth. Health Effect: impact on median healthy life years. Scale: +++ strong positive, ++ moderate positive, + weak positive, − negative.
What Budget Analysts See
OSL estimates with confidence intervals and methodology notes
Cross-country spending data showing spending-outcome relationships
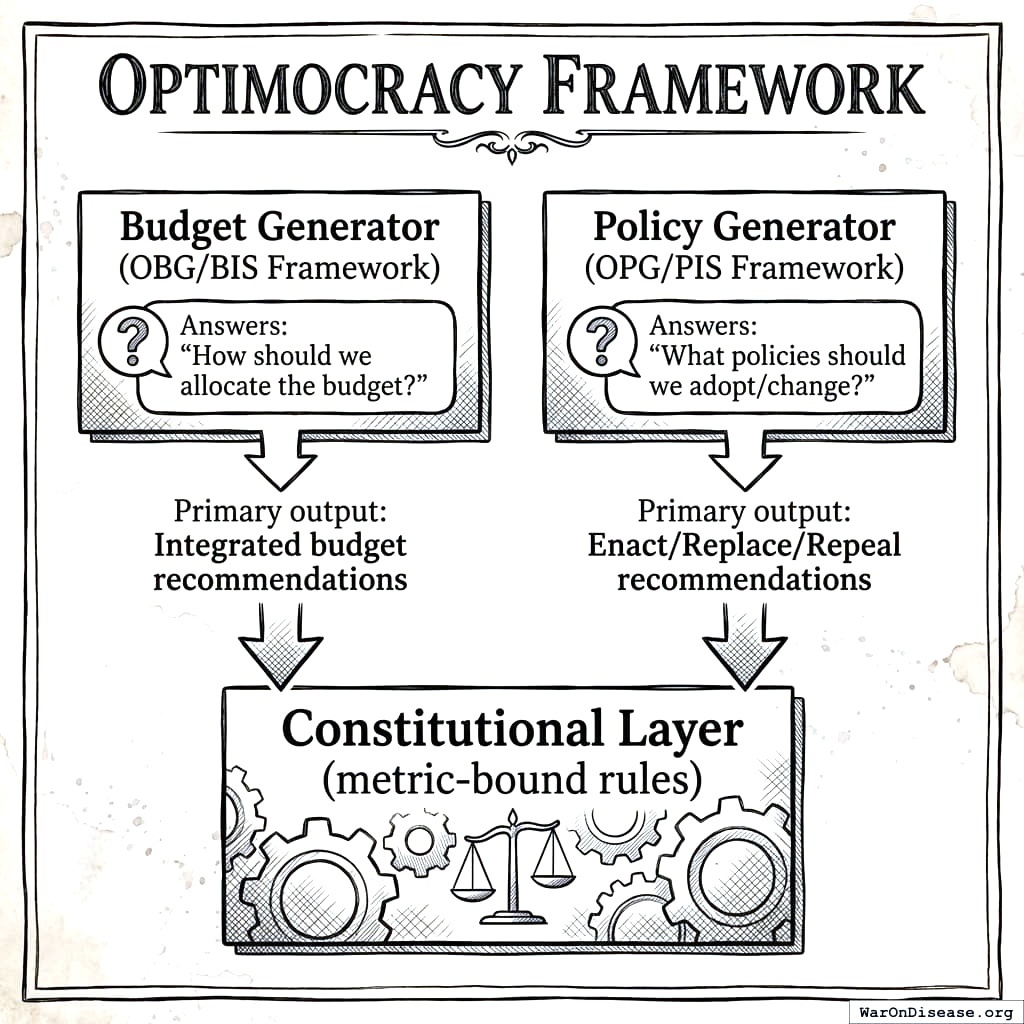
This specification focuses on generating evidence-based budget recommendations. Political implementation mechanisms are discussed separately in Incentive Alignment Bonds183.
Introduction
Why Budget Allocation Fails Today
Budget allocation is fundamentally a problem of social choice under uncertainty184. The challenge is not simply technical but institutional: current budget processes systematically diverge from welfare-optimal allocations due to political economy dynamics185,186.
Current budgets: lobbying and ‘we’ve always done it this way.’ Result: money goes to things that don’t work instead of things that do. Tradition is expensive.
Current budget allocation follows a process dominated by:
Lobbying intensity: Categories with organized beneficiaries (weapons manufacturers, agricultural lobbies) receive disproportionate funding regardless of evidence
Historical inertia: This year’s budget is last year’s budget plus a percentage, not a fresh optimization
Visible vs. invisible beneficiaries: Programs with identifiable beneficiaries (veterans) outcompete programs with diffuse beneficiaries (clinical trials, vaccinations)
Political salience: Crises drive spending regardless of cost-effectiveness (terrorism vs. air pollution)
Zero-sum framing: Budget debates treat all categories as competing rather than asking which ones are at optimal levels
The result: systematic overinvestment in low-return categories and underinvestment in high-return categories. Historical examples demonstrate the scale of missed opportunities: the smallpox eradication campaign returned an estimated 450:1 ROI136, yet similar high-return public health investments remain chronically underfunded.
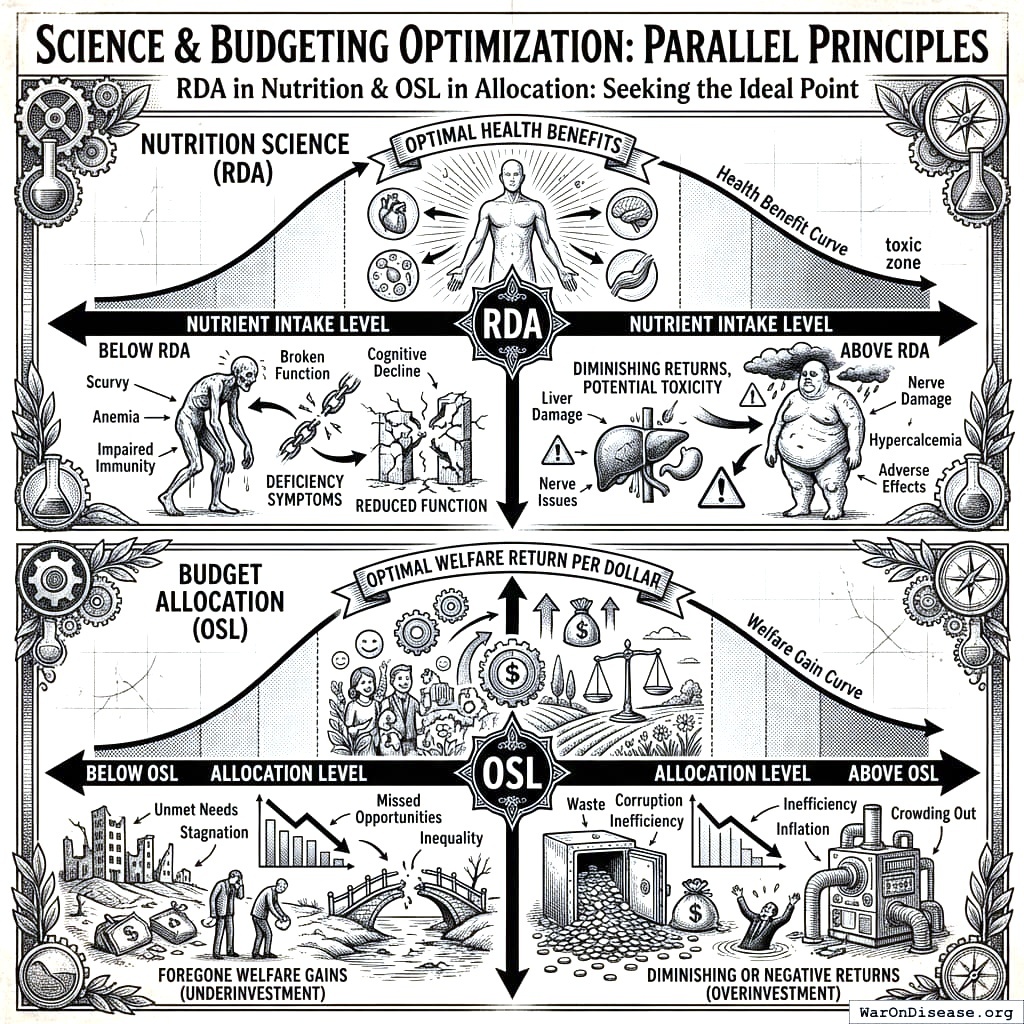
The RDA Analogy: Optimal Levels, Not Just Marginal Returns
Nutrition science doesn’t just say “eat more vitamins.” It specifies Recommended Daily Allowances - target intake levels where:
Above OSL: Diminishing or negative returns (overinvestment)
infinite spending on any category doesn’t make sense, even one with high returns. Early childhood education has excellent returns - but spending $10 trillion on it wouldn’t produce 10x the benefits of spending $1 trillion. There’s an optimal level.
Nutritionists tell you how much vitamin C you need. OSL tells governments how much education funding they need. One prevents scurvy, the other prevents stupid.
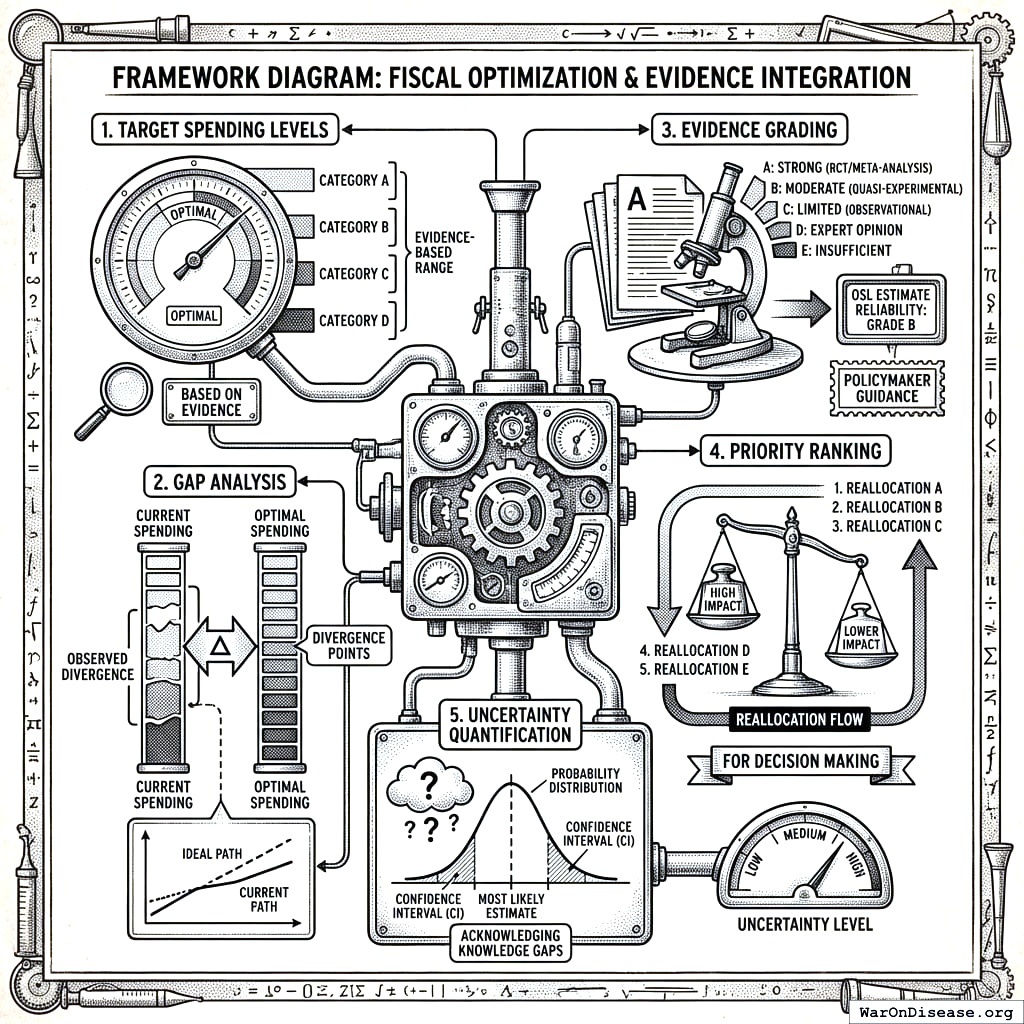
What This Framework Provides
Five pieces: evidence-based targets, gap analysis, priority ranking, uncertainty assessment, and wishful thinking. Wait, scratch that last one.
Target spending levels for each budget category based on evidence
Gap analysis showing where current spending diverges from optimal
Evidence grading so policymakers know which OSL estimates are reliable
Priority ranking for reallocation decisions
Uncertainty quantification around each estimate
Outcome Metrics: What We’re Optimizing
All OBG recommendations ultimately aim to maximize two terminal general-welfare metrics:
Real after-tax median income growth (pp/year): Year-over-year percentage change in inflation-adjusted, post-tax median household income. Sources: Census Bureau, BLS.
Median healthy life years (years): Expected years of life in good health at the population median. Sources: WHO Global Health Observatory, national health surveys.
The welfare function combines these with equal weight by default:
Why these two metrics? They are the terminal general-welfare metrics: the best currently measurable civilization-scale endpoints for approximating the terminal values defined in What Matters, pleasant consciousness and unpleasant consciousness. Most policy effects eventually show up in one or both. Economic policies (taxes, regulations, trade) primarily affect income growth. Health policies (healthcare access, public health, safety) primarily affect healthy life years. Education and infrastructure affect both. See Two-Metric Welfare Function for the complete framework.
Every spending category’s OSL is ultimately justified by its expected impact on these two metrics. The gap analysis and priority rankings reflect which reallocations would most improve the combined welfare function.
Related Work
The OBG framework builds on and extends several established traditions in public finance and evidence-based policy.
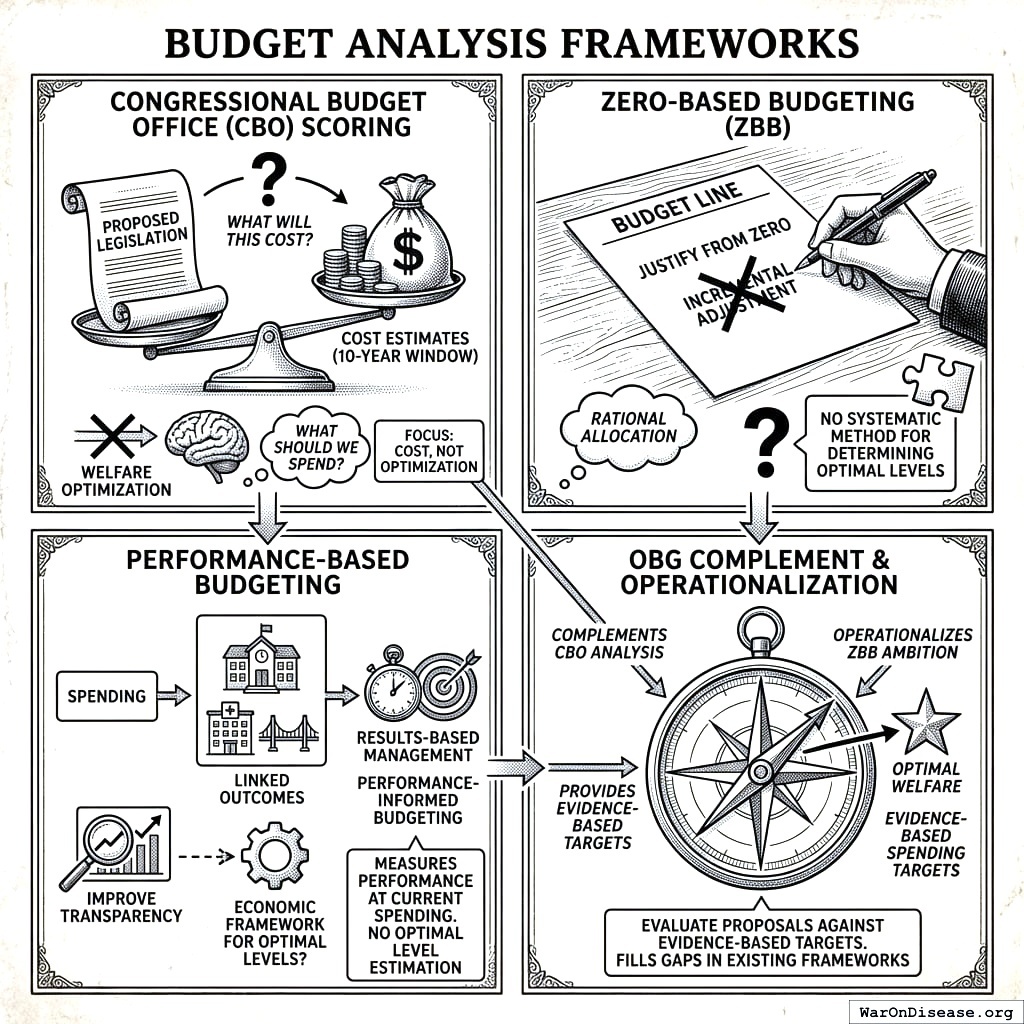
Budget Analysis Frameworks
Congressional Budget Office (CBO) Scoring. The CBO provides cost estimates for proposed legislation, projecting fiscal impacts over 10-year windows187. However, CBO scoring focuses on cost rather than welfare optimization - it answers “what will this cost?” not “what should we spend?” OBG complements CBO analysis by providing evidence-based spending targets against which proposals can be evaluated.
CBO scores costs. Performance budgeting measures results. Zero-based budgeting questions everything. OBG does all three and shows you the receipts.
Performance-Based Budgeting. Since the Planning-Programming-Budgeting System (PPBS) of the 1960s, governments have attempted to link spending to outcomes. Modern variants include Results-Based Management and Performance-Informed Budgeting. These approaches improve transparency but typically lack the economic framework for determining optimal levels - they measure performance at current spending without estimating what spending should be.
Zero-Based Budgeting. ZBB requires justifying each budget line from zero rather than incremental adjustment. While philosophically aligned with OBG’s goal of rational allocation, ZBB provides no systematic method for determining optimal levels. OBG operationalizes ZBB’s ambition with evidence-based targets.
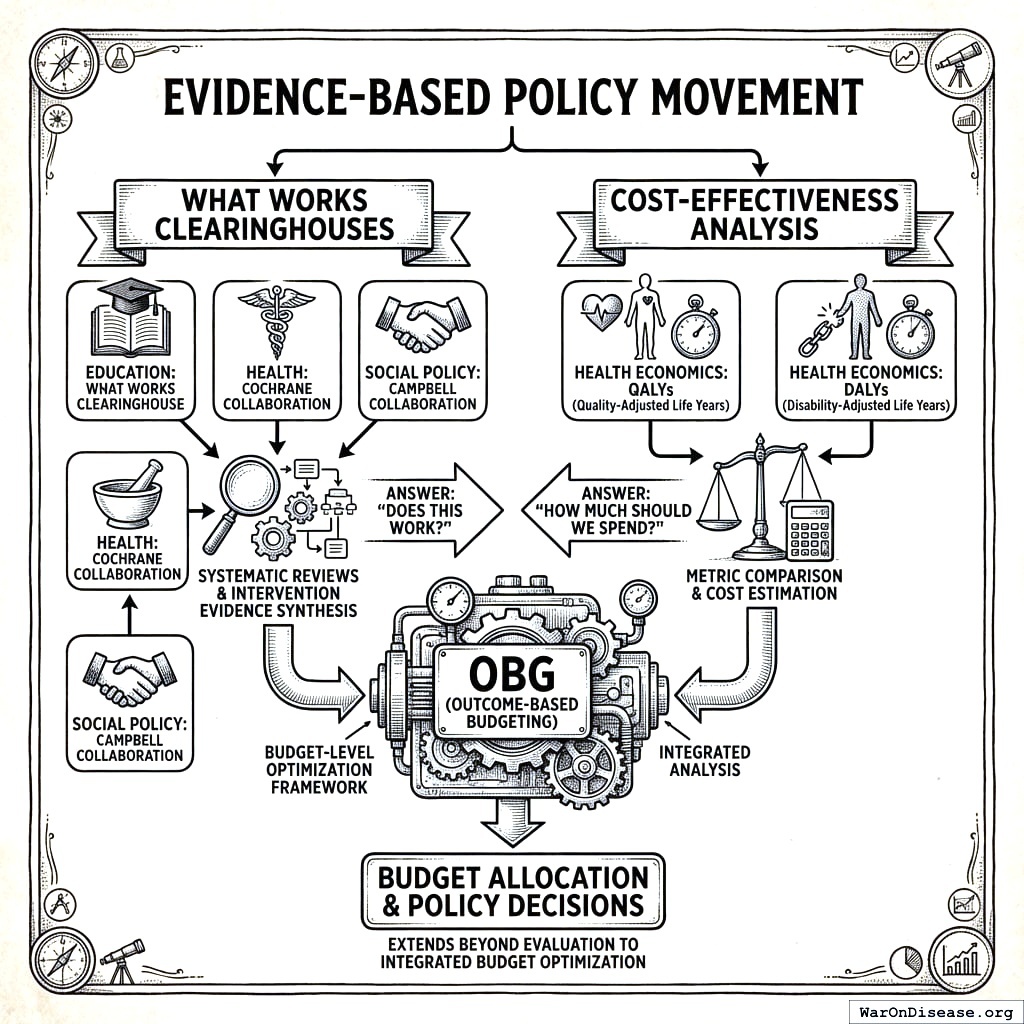
Evidence-Based Policy Movement
What Works Clearinghouses. Organizations like the What Works Clearinghouse (education), Cochrane Collaboration (health), and Campbell Collaboration (social policy) synthesize intervention evidence through systematic reviews. OBG draws on these evidence bases but extends beyond intervention evaluation to budget-level optimization. While clearinghouses answer “does this work?”, OBG answers “how much should we spend?”
Old way: evaluate programs one at a time. New way: optimize entire budgets at once. It’s like organizing your whole kitchen instead of just the spoon drawer.
Cost-Effectiveness Analysis. Health economics has developed methods for comparing interventions using metrics like QALYs (Quality-Adjusted Life Years) and DALYs (Disability-Adjusted Life Years)188. OBG incorporates cost-effectiveness as one of two estimation methods but applies it within an integrated budget optimization framework rather than intervention-by-intervention.
Comparative Public Finance
OECD Government Spending Analysis. The OECD publishes extensive cross-country spending comparisons and outcome data142,158. OBG leverages this data infrastructure for diminishing returns analysis while adding the conceptual framework of optimal levels and evidence-weighted confidence.
A conceptual model showing the methodological progression from standard OECD benchmarking to OBG’s causal identification framework and actionable spending targets.
International Benchmarking Studies. Comparative studies examine spending-outcome relationships across countries but typically stop at correlation. OBG advances this literature by incorporating causal identification methods and producing actionable spending targets.
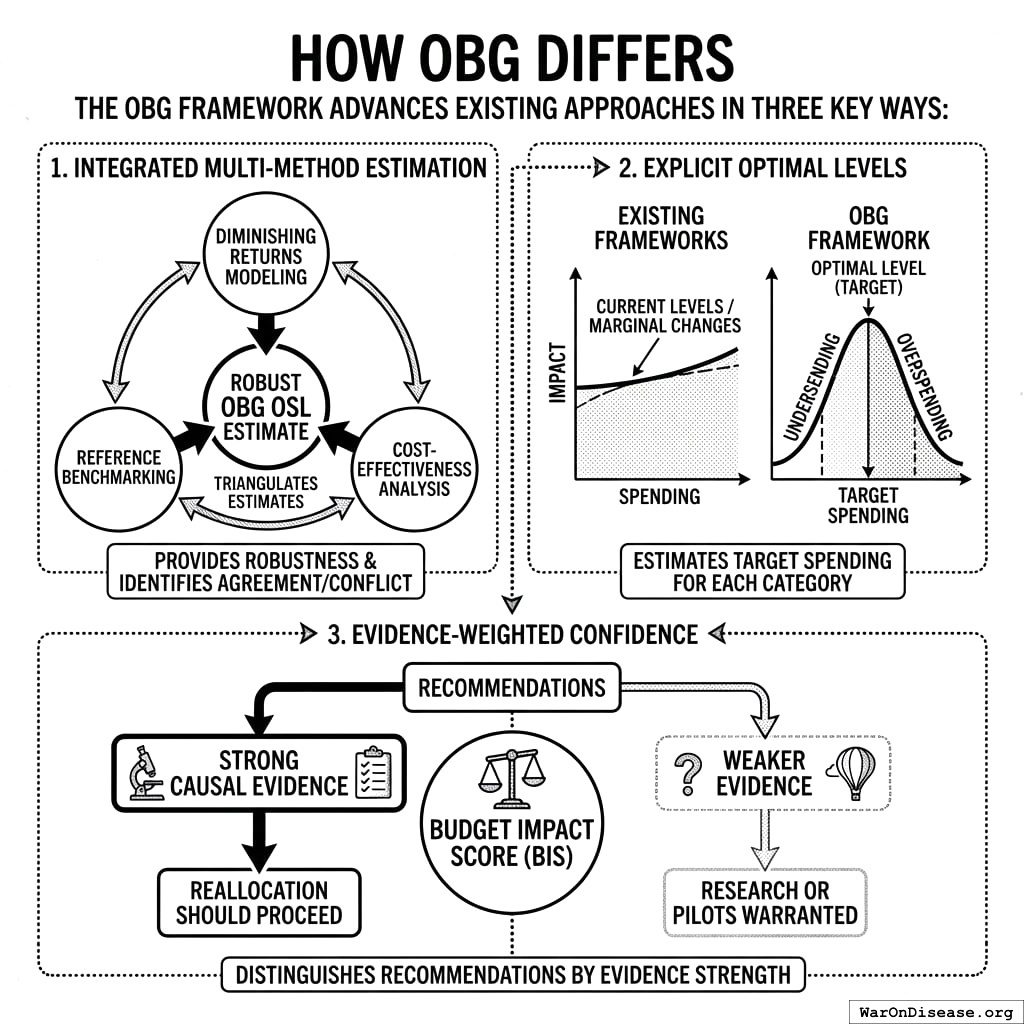
How OBG Differs
The OBG framework advances existing approaches in three key ways:
Integrated multi-method estimation. Rather than relying on a single approach, OBG combines OSL estimates from diminishing returns modeling and cost-effectiveness analysis. This provides robustness and identifies where methods agree or conflict.
Three different ways to count money, then deciding where to put it, then measuring how confident you are that you counted correctly. Like checking your restaurant bill three times because you still don’t trust yourself.
Explicit optimal levels. Unlike frameworks that analyze spending at current levels or propose marginal changes, OBG estimates target spending levels for each category - acknowledging that both underspending and overspending are suboptimal.
Evidence-weighted confidence. The Budget Impact Score (BIS) distinguishes recommendations supported by strong causal evidence (where reallocation should proceed) from those based on weaker evidence (where research or pilots are warranted).
Theoretical Framework
This section formalizes the OBG framework as a social planner’s optimization problem, establishing the theoretical foundations for optimal spending levels and evidence-weighted allocation.
A social planner is someone who plans society. They take evidence, weigh it (not literally), and decide how much money to spend on things. It’s like meal planning but for countries.
The Social Planner’s Problem
Consider a benevolent social planner allocating a fixed budget \(B\) across \(n\) spending categories. Each category generates welfare measured using the two-metric framework: real after-tax median income growth and median healthy life years.
Why these specific metrics? They are universal instrumental goods: virtually everyone wants higher purchasing power and longer healthy life, regardless of other values. They are hard to game (improving them requires actually helping typical citizens), measured by independent statistical agencies, and capture most policy effects. GDP can rise while median income stagnates; this framework correctly identifies such outcomes as low-welfare.
Let \(s_i\) denote spending on category \(i\), with \(\sum_{i=1}^{n} s_i = B\). Each category produces effects on both welfare metrics:
\(\beta_i^{inc}(s_i)\): Effect on real after-tax median income growth (pp/year)
\(\beta_i^{hlth}(s_i)\): Effect on median healthy life years (years)
Total welfare from category \(i\) follows the two-metric welfare function:
where \(\alpha = 0.5\) by default (equal weight to economic and health welfare). All welfare calculations in this framework flow through these two metrics.
Assumption 1 (Diminishing Returns). For each category \(i\), both effect functions \(\beta_i^{inc}\) and \(\beta_i^{hlth}\) are twice continuously differentiable with positive first derivatives and negative second derivatives for all \(s > 0\).
Proposition 1 (Equimarginal Principle).At the optimal allocation \(\{s_i^*\}\), marginal welfare is equalized across all categories with positive spending:
\[
W_i'(s_i^*) = \lambda^* \quad \forall i \text{ with } s_i^* > 0
\]
where \(\lambda^*\) is the shadow price of the budget constraint.
Proof. The Lagrangian is \(\mathcal{L} = \sum_i W_i(s_i) - \lambda(\sum_i s_i - B)\). First-order conditions yield \(W_i'(s_i^*) = \lambda\) for interior solutions. By strict concavity of \(W_i\), the second-order conditions are satisfied. \(\square\)
Optimal Spending Levels Under Uncertainty
In practice, the welfare functions \(W_i(\cdot)\) are not known with certainty. Let \(\hat{W}_i(s)\) denote the planner’s estimate of welfare, with associated uncertainty \(\sigma_i^2(s)\).
Definition 1 (Optimal Spending Level). The Optimal Spending Level for category \(i\) is:
where \(\rho \geq 0\) is the planner’s risk aversion parameter.
For risk-neutral planners (\(\rho = 0\)), OSL reduces to the spending level that maximizes expected welfare. For risk-averse planners, OSL accounts for estimation uncertainty.
Proposition 2 (OSL Characterization).Under Assumption 1, with estimated marginal welfare \(\hat{W}_i'(s)\) and estimation variance \(\sigma_i^2(s)\), the OSL satisfies:
where \(r\) is the social discount rate (opportunity cost of public funds).
Proof. The first-order condition for the uncertainty-adjusted maximization problem yields the result. The term \(r\) represents the marginal value of funds in alternative uses; the second term adjusts for risk. \(\square\)
Budget Impact Score as Precision Weighting
The Budget Impact Score formalizes the precision of OSL estimates, enabling evidence-weighted reallocation decisions.
Definition 2 (Budget Impact Score). For category \(i\) with \(n_i\) effect estimates \(\{\hat{\beta}_{ij}\}_{j=1}^{n_i}\), the Budget Impact Score is:
where \(\hat{\beta}_i^{pooled}\) is the quality-weighted pooled estimate of spending effects.
Three ingredients that tell you how much to trust a number: how good it is, how exact it is, and how old it is. Like checking the expiration date on milk, but for statistics.
Gap Analysis and Welfare Gains
Definition 3 (Spending Gap). The spending gap for category \(i\) is:
\[
\text{Gap}_i = \text{OSL}_i - s_i^{current}
\]
Proposition 4 (Welfare Gains from Gap Closure).For small gaps, the welfare gain from moving spending from current level to OSL is approximately:
This ranks categories by expected welfare gain adjusted for estimation confidence.
Note: In the simplified implementation (Section 10.2), we normalize by setting \(|W_i'(s_i^{current})| = 1\) for all categories, reducing the priority formula to \(\text{Priority}_i = |\text{Gap}_i| \times \text{BIS}_i\). This assumes equal marginal welfare weights across categories as a first approximation. Future iterations could incorporate category-specific marginal welfare estimates.
Welfare Bounds Under Model Uncertainty
When the functional form of \(W_i(\cdot)\) is uncertain, we can establish bounds on welfare gains.
Proposition 5 (Welfare Bounds).Let \(\underline{W}_i\) and \(\overline{W}_i\) denote lower and upper bounds on the welfare function consistent with available evidence. Then:
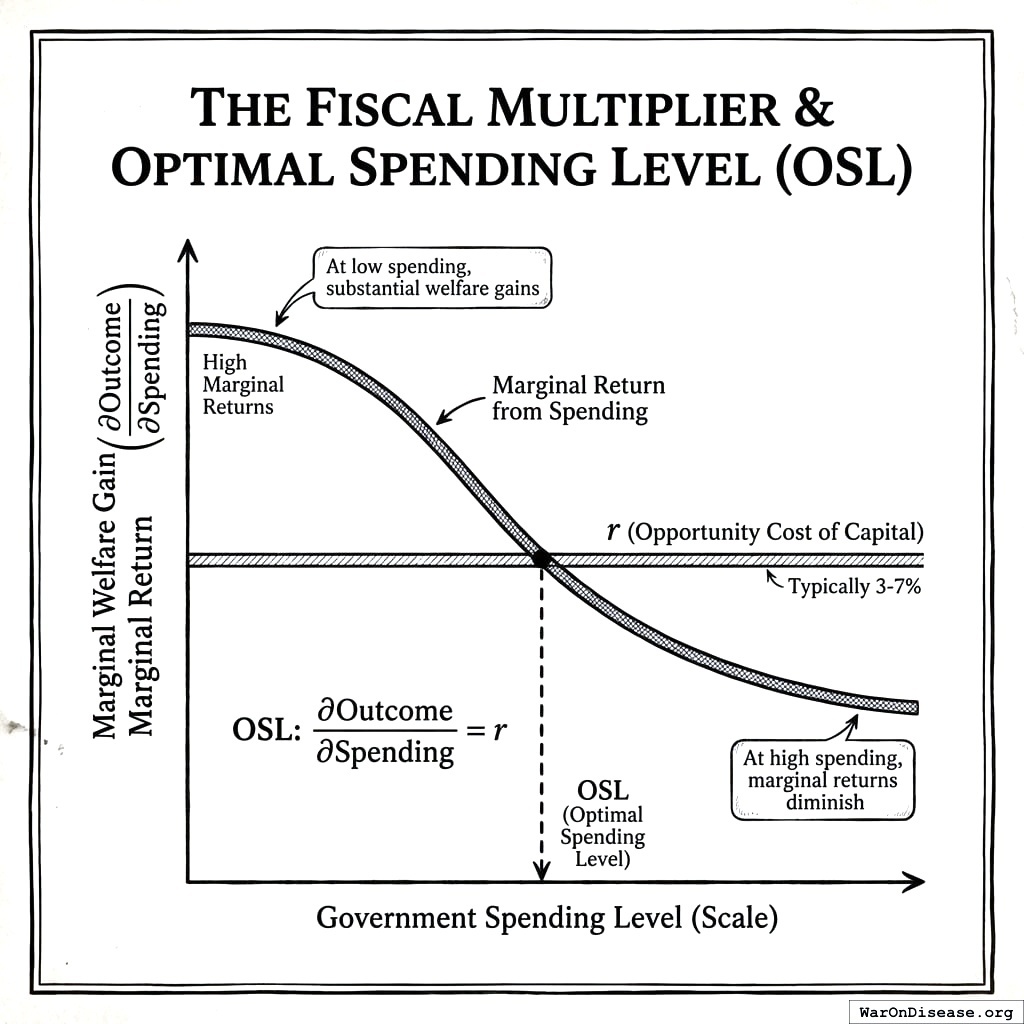
The fiscal multiplier literature establishes that spending effects vary systematically with scale189,190. At low spending levels, each additional dollar produces substantial welfare gains. At high spending levels, marginal returns diminish. The OSL is where marginal return equals opportunity cost.
The first dollar you spend helps a lot. The millionth dollar helps less. The graph tells you when to stop spending money on one thing and start spending it on another thing.
\[
\text{OSL}: \frac{\partial \text{Outcome}}{\partial \text{Spending}} = r
\]
Where \(r\) is the discount rate or opportunity cost of capital (typically 3-7%).
Finding the “Knee” of the Curve
Empirically, we look for the point where the outcome-spending relationship flattens:
Outcome
^
| ___________
| __/
| _/
| _/
| _/ <- OSL is around here
| _/
| _/
| _/
| _/
| _/
|/
+-----------------------------------> Spending
Low High
Estimate separate slopes for different spending ranges to identify where returns diminish.
3. Meta-regression of effect estimates
If multiple studies estimate effects at different spending levels, meta-regression can identify how effects vary with baseline spending. The credibility of such estimates depends critically on identification strategy191.
Worked Example: K-12 Education Spending
Primary metric affected: Real after-tax median income growth (via higher wages from improved skills).
192 exploited court-ordered school finance reforms to estimate causal effects of K-12 spending. Key finding: a 10% increase in per-pupil spending increases adult earnings by 7% for students from low-income families.
Does this effect diminish at higher spending levels?
Evidence from cross-state variation suggests:
Baseline spending (per pupil)
Effect of 10% increase
Implied marginal return
$8,000
+8% earnings
$0.80 per $1
$12,000
+5% earnings
$0.50 per $1
$16,000
+3% earnings
$0.30 per $1
$20,000
+1% earnings
$0.10 per $1
OBG estimation: At $16,000/pupil, the marginal return (~0.30) roughly equals the social discount rate. This suggests:
Evidence grade: B (strong causal identification, moderate extrapolation uncertainty)
Worked Example: Pragmatic Clinical Trials
The Highest-Return Public Investment
Metrics affected: Both real after-tax median income growth (via reduced healthcare costs and improved productivity) and median healthy life years (via better treatments). This dual impact contributes to the exceptionally high returns.
Some ways of spending government money work better than others. Also, cheap trials work as well as expensive trials, but cost less. This required two charts to explain.
Pragmatic clinical trials represent perhaps the single highest-return category of public investment identified in the literature. While vaccinations return 13:1 and early childhood education returns 4:1, pragmatic trials demonstrate benefit-cost ratios of 637 (95% CI: 479-854):1193.
The UK’s RECOVERY trial demonstrated this dramatically during COVID-19: it cost approximately $500 (95% CI: $400-$2,500) versus $41,000 (95% CI: $20,000-$120,000) for traditional Phase 3 trials, a 82x (95% CI: 21.4x-195x) cost reduction194. This single trial identified dexamethasone as a life-saving treatment, preventing an estimated 1 million deaths globally.
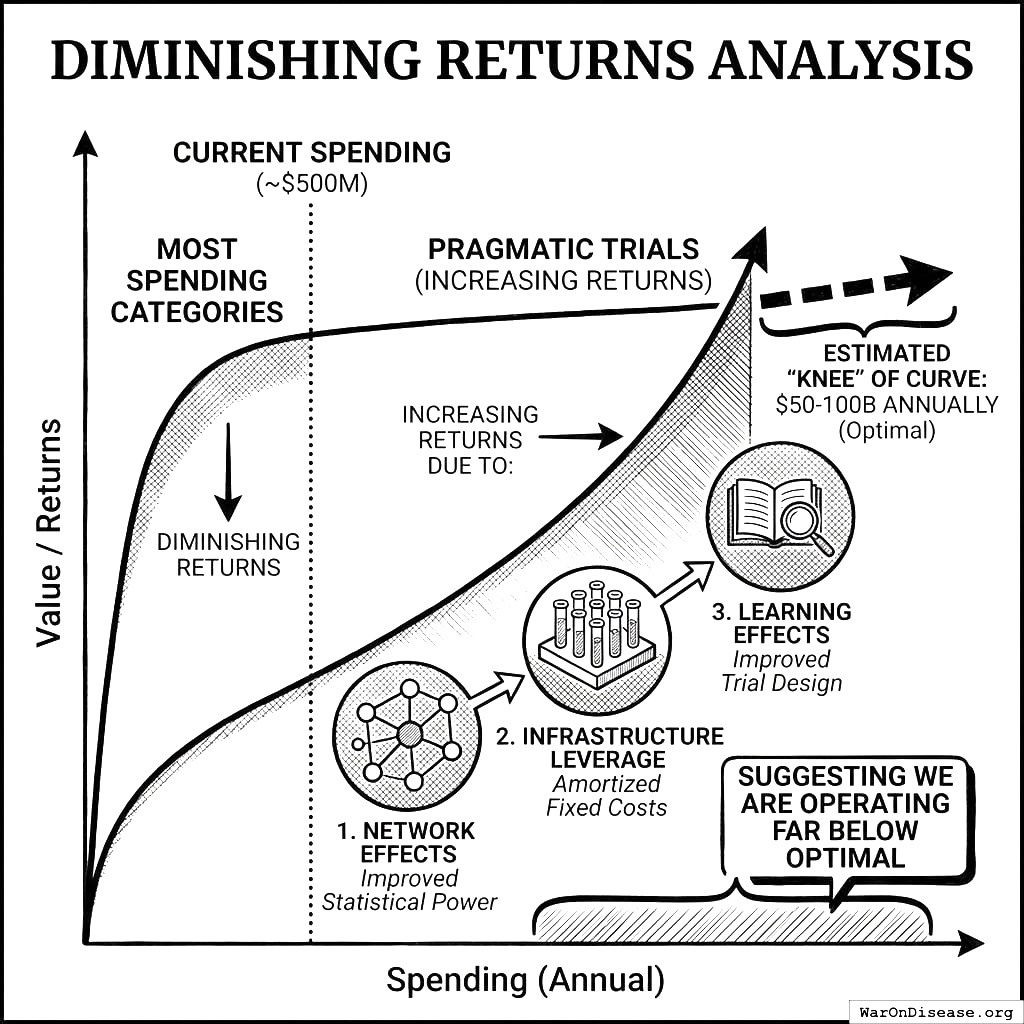
OSL Estimation
Pragmatic trials represent an innovation frontier where no country has achieved optimal investment. We estimate OSL from cost-effectiveness analysis:
The “knee” of the diminishing returns curve is estimated at $50-100B annually (vs. current ~$500M), suggesting we are operating far below optimal.
We spend 500 million on pragmatic trials. The graph says we should spend 50 to 100 billion. We are so far to the left of where we should be that we’re practically off the chart.
Among categories requiring increased investment, this is the highest priority score, exceeding outcome-funded R&D (31.5), vaccinations (25.7), and early childhood (17.0). Military spending has a larger absolute priority score (195.5) due to its massive gap, but represents overinvestment requiring reduction.
Cost-Effectiveness Threshold Analysis
The Standard Health Economics Approach
Cost-effectiveness analysis has become the standard framework for health resource allocation decisions188. The QALY (Quality-Adjusted Life Year) metric enables comparison across diverse health interventions by monetizing health outcomes at a consistent threshold195.
For health interventions, cost-effectiveness analysis provides OSL estimates:
\(\text{Scale}_i\) = target population for intervention \(i\)
\(\text{Cost}_i\) = per-person cost of intervention \(i\)
\(\text{QALY}_i\) = QALYs gained per person from intervention \(i\)
\(\text{WTP}\) = willingness-to-pay threshold (typically $50K-$150K per QALY)
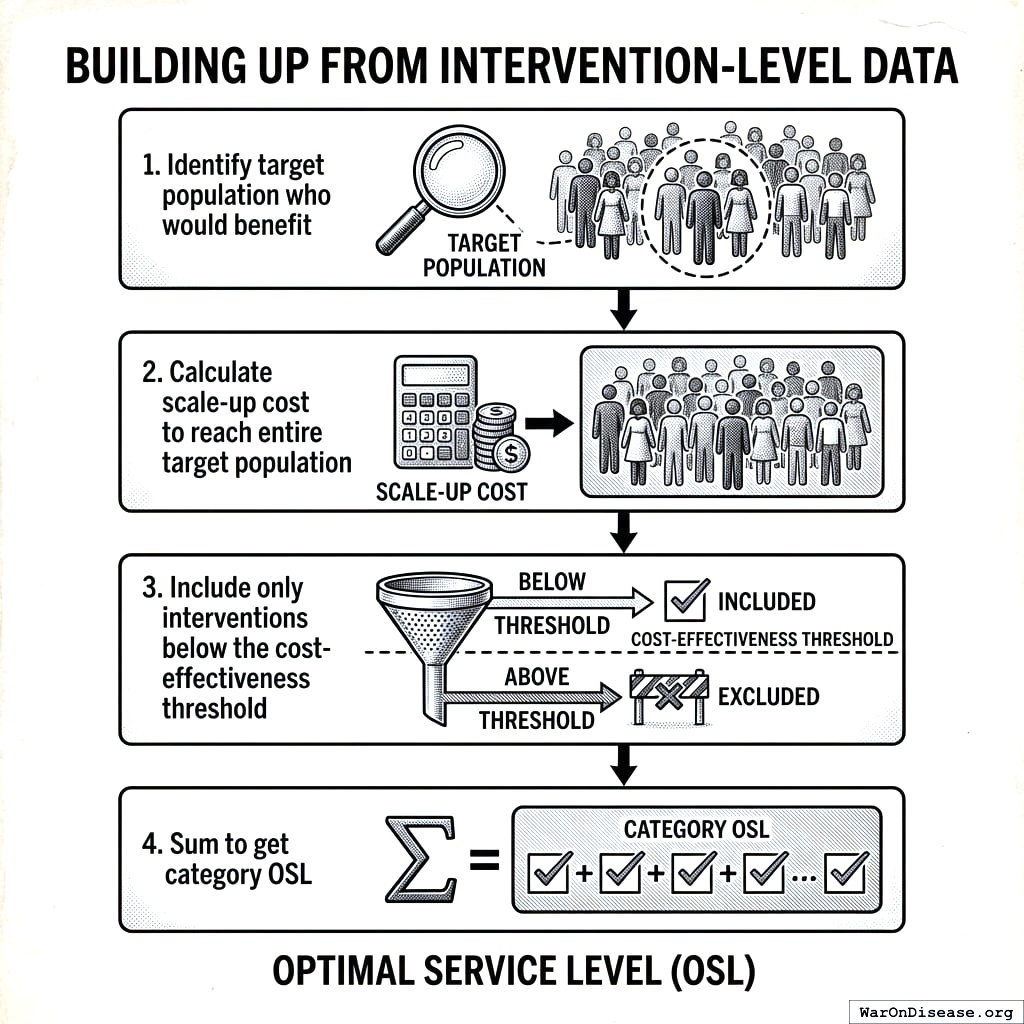
Building Up from Intervention-Level Data
Four boxes with arrows between them. The boxes show how you take lots of small numbers and turn them into one big number. Addition with extra steps.
For each health intervention with cost-effectiveness data:
Identify target population who would benefit
Calculate scale-up cost to reach entire target population
Include only interventions below the cost-effectiveness threshold
Sum to get category OSL
Worked Example: Vaccinations
Primary metric affected: Median healthy life years (via disease prevention and mortality reduction).
Vaccinations represent one of the highest-return public health investments, with estimated returns of 44:1 for routine childhood immunization17,196. The economic benefits include avoided medical costs, productivity gains, and reduced mortality16.
Cost-effectiveness estimates from CEA Registry and CDC vaccination cost studies. QALY estimates reflect average health gains across target populations; costs include vaccine acquisition, administration, and program overhead.
Intervention
Target pop.
Cost/person
QALY/person
Cost/QALY
Source
Include?
Childhood routine
4M births
$500
0.1
$5,000
CDC VFC
Yes
HPV vaccination
4M teens
$300
0.05
$6,000
CEA Registry
Yes
Flu (elderly)
50M elderly
$40
0.01
$4,000
CDC
Yes
Shingles
40M eligible
$200
0.02
$10,000
CEA Registry
Yes
COVID boosters
100M adults
$30
0.005
$6,000
CDC
Yes
All interventions fall well below the conventional $50,000-$150,000 per QALY cost-effectiveness threshold, indicating strong economic justification for full scale-up.
OBG calculation:
Childhood routine: 4M × $500 = $2.0B
HPV: 4M × $300 = $1.2B
Flu (elderly): 50M × $40 = $2.0B
Shingles: 40M × $200 = $8.0B
COVID boosters: 100M × $30 = $3.0B
Total OSL: ~$16B (vs. current ~$8B)
Gap: +$8B (underinvestment)
Evidence grade: A (RCT evidence for most vaccines, well-established cost-effectiveness)
Budget Impact Score (BIS)
The Budget Impact Score measures confidence in each category’s OSL estimate based on the quality and quantity of causal evidence. The scoring methodology draws on the established evidence hierarchy from the econometrics literature191,197.
A pyramid of trustworthiness. Randomized trials sit at the top wearing a crown. Someone’s opinion sits at the bottom, wondering what it did wrong.
BIS Calculation
For each spending category \(i\):
Step 1: Gather effect estimates
Collect all available causal effect estimates \(\{\beta_{i,1}, \beta_{i,2}, ..., \beta_{i,n_i}\}\) from the econometric literature.
Categories with large gaps AND high confidence should be addressed first.
Illustrative Example: Priority Ranking
The following uses the same illustrative data from the dashboard example above. OSL estimates for pragmatic trials, vaccinations, and K-12 education are derived in Sections 5-7. Other OSL values use cross-country benchmarking. BIS scores summarize available causal evidence quality.
Category
Current
OSL
Gap
BIS
Inc
Hlth
Priority
Action
Pragmatic trials
$0.5B
$50B
+$49.5B
0.90
++
+++
44.6
Scale 100x
Outcome-funded R&D
$45B
$90B
+$45B
0.70
++
++
31.5
Increase
Vaccinations
$8B
$35B
+$27B
0.95
+
+++
25.7
Increase
Early childhood
$50B
$70B
+$20B
0.85
+++
+
17.0
Increase
Military
$850B
$459B
-$391B
0.50
−
−
195.5
Decrease
Ag subsidies
$25B
$0B
-$25B
0.90
−
−
22.5
Eliminate
Inc = effect on real after-tax median income growth. Hlth = effect on median healthy life years. Scale: +++ strong, ++ moderate, + weak, − negative.
Reallocation plan: Cut military discretionary (-$391B) and agricultural subsidies (-$25B) to fund pragmatic clinical trials (+$49.5B), outcome-funded R&D (+$45B), vaccinations (+$27B), and early childhood (+$20B). Pragmatic trials have the highest priority score among positive-gap categories due to extreme underinvestment combined with strong evidence, and they improve both welfare metrics.
Multi-Unit Reporting
The Problem with Abstract Scores
Composite scores (like 0-1 BIS values) obscure interpretability. Policymakers and citizens understand dollars, lives, and years - not abstract indices.
Reporting at Multiple Levels
Level
Units
Use Case
Example
0. Core metrics
pp/year income growth, healthy life years
Primary welfare outcomes
“+0.1 pp income growth, +0.05 healthy years”
1. Natural
Domain-specific
Interpretation within domain
“Education: $2,100/student gap”
2. Monetized
$ equivalent
Cross-domain comparison
“Expected welfare gain: $4.00 per $1”
3. Health
QALYs/DALYs
Health-weighted comparison
“12,000 QALYs per $1B invested”
4. Composite
0-1 score
Ranking when monetization uncertain
“BIS = 0.85”
Level 0 (Core Metrics) reports expected changes to the two welfare metrics directly. All other levels are derived from or convertible to these core outcomes. QALYs (Level 3) translate directly to median healthy life years. Monetized values (Level 2) combine income effects with health effects valued at standard rates.
Recommendation: Moderate underinvestment with strong evidence. Closing the gap would yield ~$80B in NPV returns.
Quality Requirements and Validation
Minimum Thresholds for OBG Estimation
Criterion
Minimum
Rationale
Reference countries
5+
Avoid outlier bias
Dose-response studies
3+
Identify diminishing returns
Causal effect estimates
2+
Cross-validate
Data recency
Within 10 years
Relevance
BIS for reallocation
> 0.40
Sufficient confidence
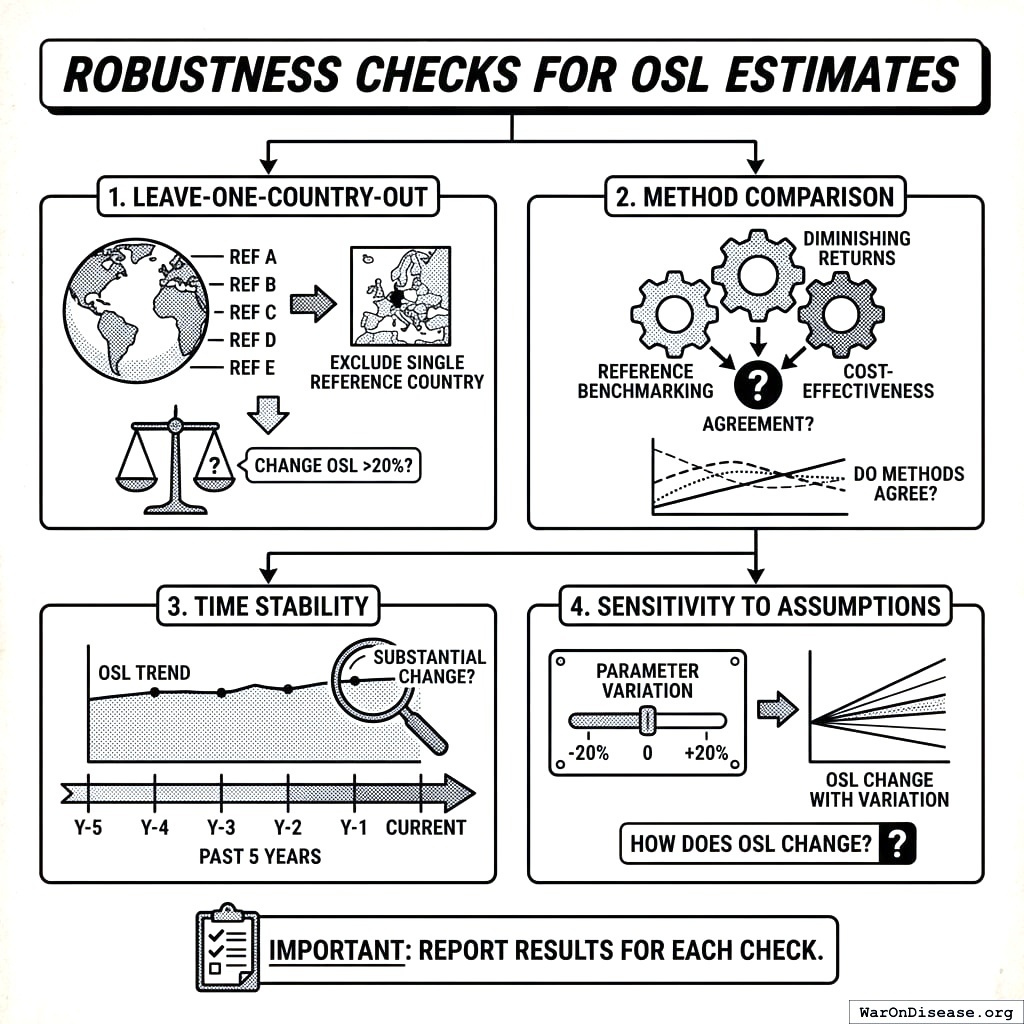
Robustness Checks
For each OSL estimate, report:
Leave-one-country-out: Does excluding any single country change OSL by >20%?
Method comparison: Do diminishing returns and cost-effectiveness methods agree?
Time stability: Has OSL changed substantially over past 5 years?
Sensitivity to assumptions: How does OSL change with ±20% parameter variation?
Four ways to check if your answer is wrong. Look for weird numbers. Make sure you did the same thing every time. Check if it changes when time passes. Wiggle the inputs and see if it explodes.
Interpreting Results
Gap Ranges and Recommended Actions
Gap (% of current)
Interpretation
Recommended Action
> +50%
Severe underinvestment
Immediate scale-up
+20% to +50%
Moderate underinvestment
Phased increase
-10% to +20%
Near optimal
Monitor, fine-tune
-50% to -10%
Moderate overinvestment
Gradual reduction
< -50%
Severe overinvestment
Urgent reallocation
What the Algorithm Cannot Tell You
Factor
OBG Captures
OBG Does Not Capture
Evidence-optimal spending level
Yes
Confidence in estimates
Yes
Direction of reallocation
Yes
Political feasibility
No
Implementation capacity
No
Transition costs
No
Distributional effects
No
Novel interventions
No
OBG provides evidence-based targets. Political judgment is still required for implementation strategy.
Pilot Program Prioritization
Value of Information for Uncertain Categories
Categories with low BIS but potentially high returns warrant research investment:
High-VOI categories should receive pilot funding to generate better evidence.
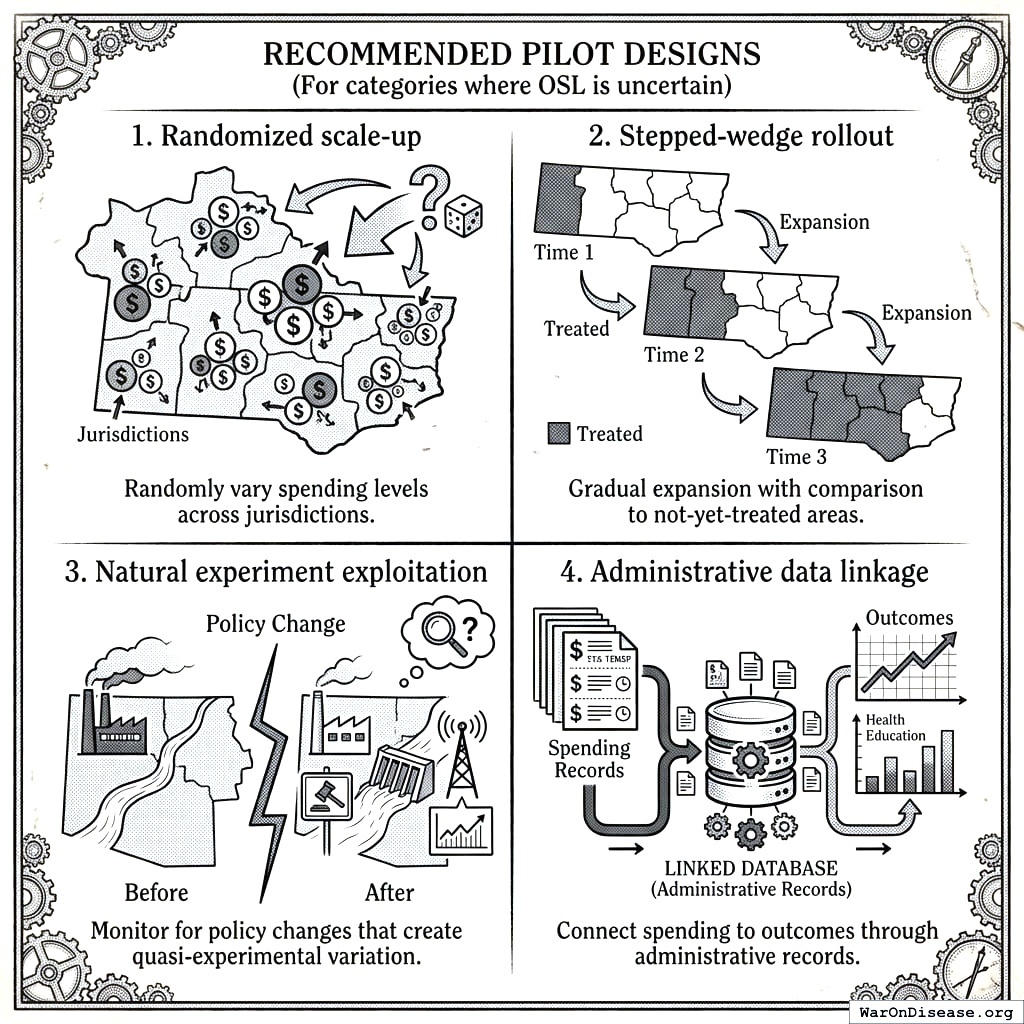
Recommended Pilot Designs
Four ways to test if your idea works before spending billions. Option 1: flip a coin. Option 2: do it slowly. Option 3: wait for something to happen and watch. Option 4: check if someone already wrote it down.
For categories where OSL is uncertain:
Randomized scale-up: Randomly vary spending levels across jurisdictions
Stepped-wedge rollout: Gradual expansion with comparison to not-yet-treated areas
Natural experiment exploitation: Monitor for policy changes that create quasi-experimental variation
Administrative data linkage: Connect spending to outcomes through administrative records
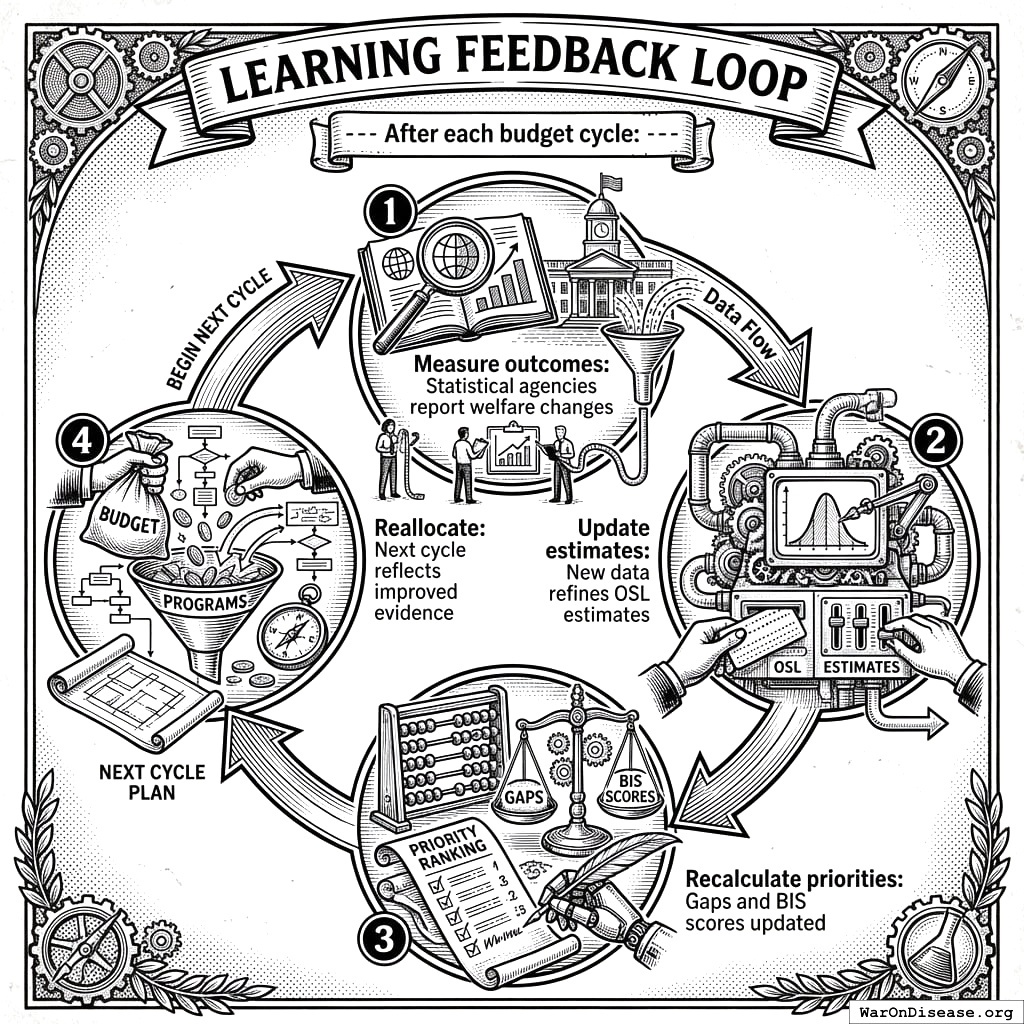
Learning Feedback Loop
A circle with four boxes in it. The boxes say: spend money, see what happened, learn from it, spend money differently. Then you go around the circle again. It’s like learning from your mistakes, but on purpose.
Recalculate priorities: Gaps and BIS scores updated
Reallocate: Next cycle reflects improved evidence
Data Sources
Cross-Country Databases
International organizations maintain standardized cross-country spending and outcome data essential for diminishing returns analysis. The OECD provides the most comprehensive harmonized data for high-income countries142.
These databases enable systematic ranking of interventions by cost-effectiveness. For example, deworming programs consistently rank among the most cost-effective health interventions, with costs as low as $30-50 per DALY averted33.
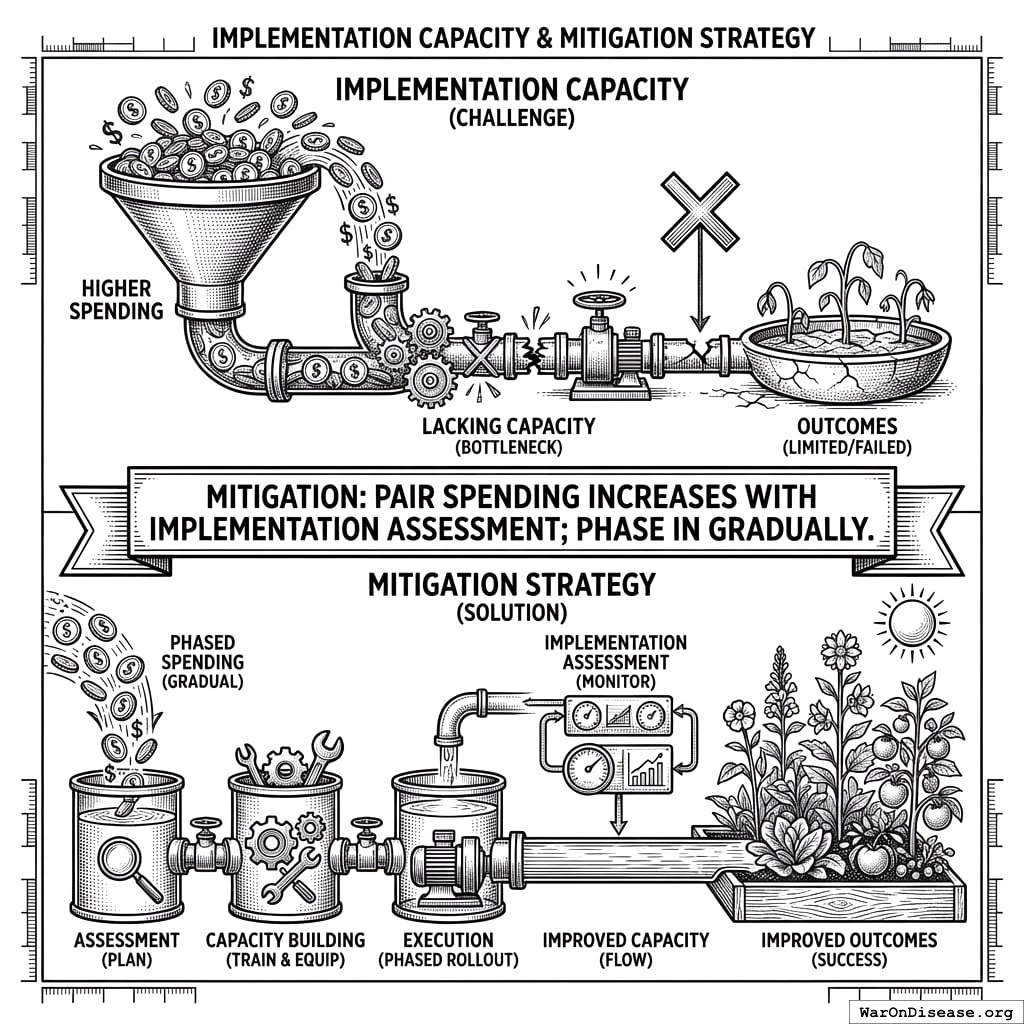
Higher spending may not translate to outcomes if implementation capacity is lacking.
Money goes through two filters before it becomes results. The filters are called ‘make sure you can actually do this’ and ‘do it slowly so you don’t mess up.’ Filters for money that don’t involve coffee.
Mitigation: Pair spending increases with implementation assessment; phase in gradually.
Benchmarking Framework
This section defines how OBG should be benchmarked against historical and prospective budget outcomes.
Retrospective Validation
Question: Did jurisdictions that moved toward OSL achieve better outcomes than those that diverged?
Three steps to check if you were right. Step 1: go back in time (mathematically). Step 2: pretend you did what you should have done. Step 3: compare it to what actually happened. Like replaying a football match in your head where you win.
Method: 1. Compute OSL for past periods using only data available at that time (to avoid lookahead bias) 2. Identify jurisdictions that moved toward/away from OSL 3. Compare subsequent outcomes using difference-in-differences or synthetic control methods212
Example: US State Education Spending 2000-2015
A retrospective analysis can examine whether states that moved toward education OSL (estimated from high-performing states like Massachusetts and Minnesota) subsequently showed improved test scores and graduation rates relative to states that diverged.
Challenges:
Confounding from simultaneous policy changes
Limited variation in spending changes within countries
Outcome measurement lags (education effects take years to materialize)
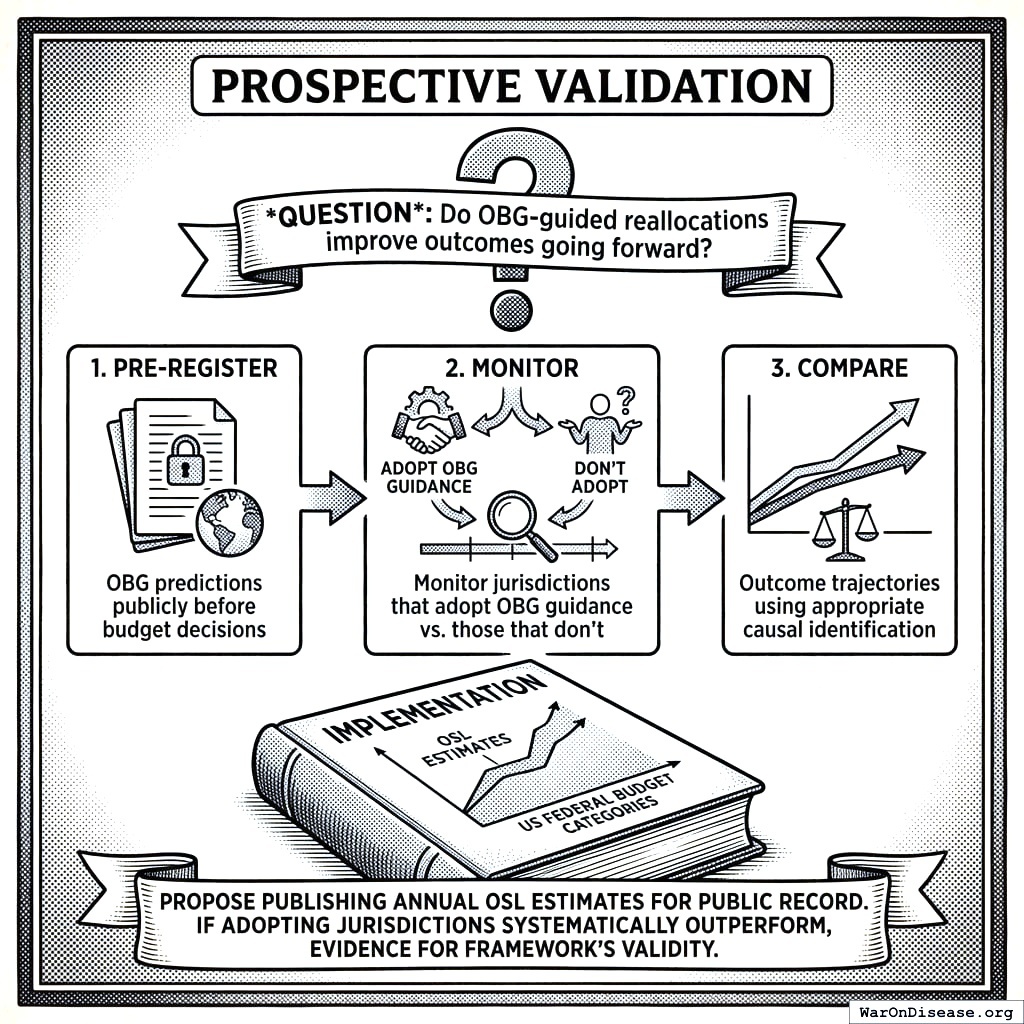
Prospective Validation
Question: Do OBG-guided reallocations improve outcomes going forward?
How to prove you’re not making things up. Write down your prediction before it happens. Tell everyone. Wait. Check if you were right. It’s the scientific method for not lying to yourself.
Method: 1. Pre-register OBG predictions publicly before budget decisions 2. Monitor jurisdictions that adopt OBG guidance vs. those that don’t 3. Compare outcome trajectories using appropriate causal identification
Implementation: Publish annual OSL estimates for US federal budget categories, creating a public record for prospective benchmarking. If jurisdictions that adopt OBG guidance systematically outperform those that do not, the framework is doing its job.
Success Metrics
Metric
Definition
Target
Interpretation
Gap reduction
Did spending move toward OSL?
> 50% of gap closed in 10 years
Tests political feasibility
Outcome improvement
Did welfare metrics improve more in OBG-following jurisdictions?
> 10% relative improvement
Tests welfare prediction accuracy
Prediction accuracy
Did estimated returns match actual returns?
Correlation r > 0.5
Tests underlying model
Cross-method consistency
Do diminishing returns and cost-effectiveness methods converge?
Agreement within 30%
Tests methodological robustness
Evidence Base and Benchmarking
OBG rests on the underlying studies cited throughout (e.g.,192 for education,196 for vaccinations) plus a continuous benchmarking program:
Data collection: Longitudinal spending and outcome data across jurisdictions
Historical OSL estimation: Compute past OSL using only contemporaneously available data
Publication: Publish pre-registered benchmark studies and annual scorecards
Sensitivity Analysis
Parameter Sensitivity
Parameter
Default
Test Range
Impact on OSL
Country data set
All OECD
OECD + G20, High-income only
±15%
Discount rate
5%
3-7%
±20%
BIS confidence threshold
0.40
0.30-0.60
Category inclusion
Recency decay rate
0.03/year
0.01-0.05
Estimate weights
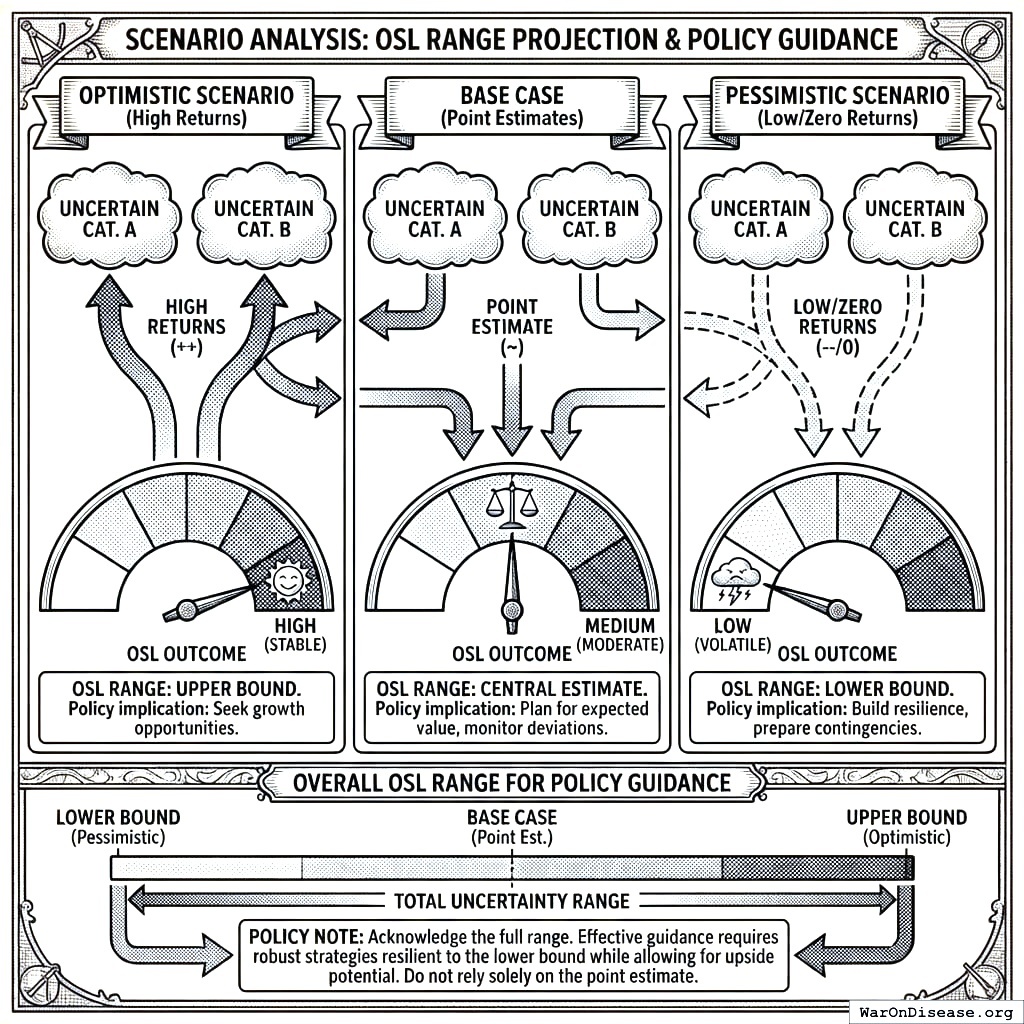
Scenario Analysis
Optimistic scenario: All uncertain categories have high returns Pessimistic scenario: Uncertain categories have low/zero returns Base case: Use point estimates
Report OSL range across scenarios for policy guidance.
Three answers to the same question. The pessimistic one assumes everything will go wrong. The optimistic one assumes everything will go right. The base case assumes you’ll be disappointed but not surprised.
Conclusion
The Optimal Budget Generator framework provides a systematic, evidence-based approach to budget allocation. Unlike marginal-return frameworks that can justify infinite spending on high-return categories, OBG recognizes that every category has an optimal level - like the Recommended Daily Allowance for nutrients.
The framework answers three questions:
What is the target? OBG provides evidence-based spending levels for each category
How far are we? Gap analysis shows where current spending diverges from optimal
How confident are we? BIS scores evidence quality so policymakers know which OSL estimates are reliable
Even with imperfect evidence, systematically moving from severe misallocation (military 100% above OSL, vaccinations 75% below OSL) toward evidence-based targets should produce substantially larger welfare gains than current lobbying-driven allocation achieves.
Acknowledgments
The author thanks seminar participants and anonymous reviewers for helpful comments and suggestions. All errors remain the author’s own.
References
1.
NIH Common Fund. NIH pragmatic trials: Minimal funding despite 30x cost advantage. NIH Common Fund: HCS Research Collaboratoryhttps://commonfund.nih.gov/hcscollaboratory (2025)
The NIH Pragmatic Trials Collaboratory funds trials at $500K for planning phase, $1M/year for implementation-a tiny fraction of NIH’s budget. The ADAPTABLE trial cost $14 million for 15,076 patients (= $929/patient) versus $420 million for a similar traditional RCT (30x cheaper), yet pragmatic trials remain severely underfunded. PCORnet infrastructure enables real-world trials embedded in healthcare systems, but receives minimal support compared to basic research funding. Additional sources: https://commonfund.nih.gov/hcscollaboratory | https://pcornet.org/wp-content/uploads/2025/08/ADAPTABLE_Lay_Summary_21JUL2025.pdf | https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5604499/
Chance of American dying in foreign-born terrorist attack: 1 in 3.6 million per year (1975-2015) Including 9/11 deaths; annual murder rate is 253x higher than terrorism death rate More likely to die from lightning strike than foreign terrorism Note: Comprehensive 41-year study shows terrorism risk is extremely low compared to everyday dangers Additional sources: https://www.cato.org/policy-analysis/terrorism-immigration-risk-analysis | https://www.nbcnews.com/news/us-news/you-re-more-likely-die-choking-be-killed-foreign-terrorists-n715141
Mean exclusion rate: 86.1% across 158 antidepressant efficacy trials (range: 44.4% to 99.8%) More than 82% of real-world depression patients would be ineligible for antidepressant registration trials Exclusion rates increased over time: 91.4% (2010-2014) vs. 83.8% (1995-2009) Most common exclusions: comorbid psychiatric disorders, age restrictions, insufficient depression severity, medical conditions Emergency psychiatry patients: only 3.3% eligible (96.7% excluded) when applying 9 common exclusion criteria Only a minority of depressed patients seen in clinical practice are likely to be eligible for most AETs Note: Generalizability of antidepressant trials has decreased over time, with increasingly stringent exclusion criteria eliminating patients who would actually use the drugs in clinical practice Additional sources: https://pubmed.ncbi.nlm.nih.gov/26276679/ | https://pubmed.ncbi.nlm.nih.gov/26164052/ | https://www.wolterskluwer.com/en/news/antidepressant-trials-exclude-most-real-world-patients-with-depression
Berkshire’s compounded annual return from 1965 through 2024 was 19.9%, nearly double the 10.4% recorded by the S&P 500. Berkshire shares skyrocketed 5,502,284% compared to the S&P 500’s 39,054% rise during that period. Additional sources: https://www.cnbc.com/2025/05/05/warren-buffetts-return-tally-after-60-years-5502284percent.html | https://www.slickcharts.com/berkshire-hathaway/returns
Comprehensive mortality and morbidity data by cause, age, sex, country, and year Global mortality: 55-60 million deaths annually Lives saved by modern medicine (vaccines, cardiovascular drugs, oncology): 12M annually (conservative aggregate) Leading causes of death: Cardiovascular disease (17.9M), Cancer (10.3M), Respiratory disease (4.0M) Note: Baseline data for regulatory mortality analysis. Conservative estimate of pharmaceutical impact based on WHO immunization data (4.5M/year from vaccines) + cardiovascular interventions (3.3M/year) + oncology (1.5M/year) + other therapies. Additional sources: https://www.who.int/data/gho/data/themes/mortality-and-global-health-estimates
General range: $3,000-$5,500 per life saved (GiveWell top charities) Helen Keller International (Vitamin A): $3,500 average (2022-2024); varies $1,000-$8,500 by country Against Malaria Foundation: $5,500 per life saved New Incentives (vaccination incentives): $4,500 per life saved Malaria Consortium (seasonal malaria chemoprevention): $3,500 per life saved VAS program details: $2 to provide vitamin A supplements to child for one year Note: Figures accurate for 2024. Helen Keller VAS program has wide country variation ($1K-$8.5K) but $3,500 is accurate average. Among most cost-effective interventions globally Additional sources: https://www.givewell.org/charities/top-charities | https://www.givewell.org/charities/helen-keller-international | https://ourworldindata.org/cost-effectiveness
The cost of 5.56mm NATO ammunition at military bulk procurement rates is approximately $0.40 per round, based on Lake City Army Ammunition Plant production and commercial market floor prices for mil-spec M855 ammunition.
The General Accounting Office reports that US forces used 1.8 billion rounds of small-arms ammunition per year, a level that more than doubled in five years. An estimated 250,000 rounds were fired for every insurgent killed in Iraq and Afghanistan.
Average family caregiver: 25-26 hours per week (100-104 hours per month) 38 million caregivers providing 36 billion hours of care annually Economic value: $16.59 per hour = $600 billion total annual value (2021) 28% of people provided eldercare on a given day, averaging 3.9 hours when providing care Caregivers living with care recipient: 37.4 hours per week Caregivers not living with recipient: 23.7 hours per week Note: Disease-related caregiving is subset of total; includes elderly care, disability care, and child care Additional sources: https://www.aarp.org/caregiving/financial-legal/info-2023/unpaid-caregivers-provide-billions-in-care.html | https://www.bls.gov/news.release/elcare.nr0.htm | https://www.caregiver.org/resource/caregiver-statistics-demographics/
Forbes identified a record 2,781 billionaires worldwide with combined net worth of $14.2 trillion, 141 more than 2023. Bernard Arnault (LVMH) topped the list at $233 billion.
US programs (1994-2023): $540B direct savings, $2.7T societal savings ( $18B/year direct, $90B/year societal) Global (2001-2020): $820B value for 10 diseases in 73 countries ( $41B/year) ROI: $11 return per $1 invested Measles vaccination alone saved 93.7M lives (61% of 154M total) over 50 years (1974-2024) Additional sources: https://www.cdc.gov/mmwr/volumes/73/wr/mm7331a2.htm | https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(24)00850-X/fulltext
CPI-U (1980): 82.4 CPI-U (2024): 313.5 Inflation multiplier (1980-2024): 3.80× Cumulative inflation: 280.48% Average annual inflation rate: 3.08% Note: Official U.S. government inflation data using Consumer Price Index for All Urban Consumers (CPI-U). Additional sources: https://www.bls.gov/data/inflation_calculator.htm
Explores the aggregation of information in groups, arguing that decisions are often better than could have been made by any single member of the group. The opening anecdote relates Francis Galton’s surprise that the crowd at a county fair accurately guessed the weight of an ox when the median of their individual guesses was taken. The three conditions for a group to be intelligent are diversity, independence, and decentralization. Additional sources: https://archive.org/details/wisdomofcrowds0000suro | https://en.wikipedia.org/wiki/The_Wisdom_of_Crowds | https://www.amazon.com/Wisdom-Crowds-James-Surowiecki/dp/0385721706
.
22.
ClinicalTrials.gov API v2 direct analysis. ClinicalTrials.gov cumulative enrollment data (2025). Direct analysis via ClinicalTrials.gov API v2https://clinicaltrials.gov/data-api/api
Analysis of 100,000 active/recruiting/completed trials on ClinicalTrials.gov (as of January 2025) shows cumulative enrollment of 12.2 million participants: Phase 1 (722k), Phase 2 (2.2M), Phase 3 (6.5M), Phase 4 (2.7M). Median participants per trial: Phase 1 (33), Phase 2 (60), Phase 3 (237), Phase 4 (90). Additional sources: https://clinicaltrials.gov/data-api/api
Only 3-5% of adult cancer patients in US receive treatment within clinical trials About 5% of American adults have ever participated in any clinical trial Oncology: 2-3% of all oncology patients participate Contrast: 50-60% enrollment for pediatric cancer trials (<15 years old) Note: 20% of cancer trials fail due to insufficient enrollment; 11% of research sites enroll zero patients Additional sources: https://www.fightcancer.org/policy-resources/barriers-patient-enrollment-therapeutic-clinical-trials-cancer | https://hints.cancer.gov/docs/Briefs/HINTS_Brief_48.pdf
2.3 billion individuals had more than five ailments (2013) Chronic conditions caused 74% of all deaths worldwide (2019), up from 67% (2010) Approximately 1 in 3 adults suffer from multiple chronic conditions (MCCs) Risk factor exposures: 2B exposed to biomass fuel, 1B to air pollution, 1B smokers Projected economic cost: $47 trillion by 2030 Note: 2.3B with 5+ ailments is more accurate than "2B with chronic disease." One-third of all adults globally have multiple chronic conditions Additional sources: https://www.sciencedaily.com/releases/2015/06/150608081753.htm | https://pmc.ncbi.nlm.nih.gov/articles/PMC10830426/ | https://pmc.ncbi.nlm.nih.gov/articles/PMC6214883/
Approximately 12% of trials with results posted on the ClinicalTrials.gov results database (905/7,646) were terminated. Primary reasons: insufficient accrual (57% of non-data-driven terminations), business/strategic reasons, and efficacy/toxicity findings (21% data-driven terminations).
Global clinical trials market valued at approximately $83 billion in 2024, with projections to reach $83-132 billion by 2030. Additional sources: https://www.globenewswire.com/news-release/2024/04/19/2866012/0/en/Global-Clinical-Trials-Market-Research-Report-2024-An-83-16-Billion-Market-by-2030-AI-Machine-Learning-and-Blockchain-will-Transform-the-Clinical-Trials-Landscape.html | https://www.precedenceresearch.com/clinical-trials-market
Military sector federal lobbying totaled $198,009,793 in 2025, up from $159.5 million in 2024 and $142.9 million in 2023. Additional sources: https://www.opensecrets.org/federal-lobbying/sectors/summary?id=D
BAE Systems market capitalization approx $75.80B and Thales approx $56.68B as of June 2026, combined approx $132.5B for the two major allied European military primes. Additional sources: https://companiesmarketcap.com/thales/marketcap/
Combined market capitalization of 11 US military primes approx $835.8B at the 2026-06-11 close: RTX $248.07B, Boeing $174.71B, Lockheed Martin $126.51B, General Dynamics $96.90B, Northrop Grumman $78.48B, L3Harris $58.16B, Leidos $15.36B, Huntington Ingalls $11.86B, CACI $11.61B, Booz Allen Hamilton $9.24B, SAIC $4.86B. Tradeable float across the 13 Western primes (adding BAE Systems and Thales) approx $880B, about 91 percent of combined cap (range $850-900B), from per-company float and shares-outstanding statistics pages; big-5 floats verified individually (RTX 92.6%, BA 96.0%, LMT 85.7%, GD 94.2%, NOC 99.7%); Thales is the outlier at approx 45% float because the French State (26.60%) and Dassault Aviation (26.59%) stakes are locked. Additional sources: https://stockanalysis.com/stocks/rtx/statistics/ | https://www.dassault-aviation.com/en/group/about-us/shareholding-structure-and-organization-chart/
Political scientist R.J. Rummel’s comprehensive accounting of democide (government murder of unarmed civilians) in the 20th century. His final revised estimate: 262 million people murdered by their own governments from 1900-1999, excluding battle deaths in wars. Range: 200-272+ million. Communist regimes account for the largest share (100-148+ million). Updated figures at hawaii.edu/powerkills.
Schistosomiasis treatment: $28.19-$70.48 per DALY (using arithmetic means with varying disability weights) Soil-transmitted helminths (STH) treatment: $82.54 per DALY (midpoint estimate) Note: GiveWell explicitly states this 2011 analysis is "out of date" and their current methodology focuses on long-term income effects rather than short-term health DALYs Additional sources: https://www.givewell.org/international/technical/programs/deworming/cost-effectiveness
Calculated from IHME Global Burden of Disease (2.55B DALYs) and global GDP per capita valuation. $109 trillion annual global disease burden.
The global economic burden of disease, including direct healthcare costs ($8.2 trillion) and lost productivity ($100.9 trillion from 2.55 billion DALYs × $39,570 per DALY), totals approximately $109.1 trillion annually.
Phase I duration: 2.3 years average Total time to market (Phase I-III + approval): 10.5 years average Phase transition success rates: Phase I→II: 63.2%, Phase II→III: 30.7%, Phase III→Approval: 58.1% Overall probability of approval from Phase I: 12% Note: Largest publicly available study of clinical trial success rates. Efficacy lag = 10.5 - 2.3 = 8.2 years post-safety verification. Additional sources: https://go.bio.org/rs/490-EHZ-999/images/ClinicalDevelopmentSuccessRates2011_2020.pdf
Approximately 30% of drugs gain at least one new indication after initial approval. Additional sources: https://www.nature.com/articles/s41591-024-03233-x
Early childhood education: Benefits 12X outlays by 2050; $8.70 per dollar over lifetime Educational facilities: $1 spent → $1.50 economic returns Energy efficiency comparison: 2-to-1 benefit-to-cost ratio (McKinsey) Private return to schooling: 9% per additional year (World Bank meta-analysis) Note: 2.1 multiplier aligns with benefit-to-cost ratios for educational infrastructure/energy efficiency. Early childhood education shows much higher returns (12X by 2050) Additional sources: https://www.epi.org/publication/bp348-public-investments-outside-core-infrastructure/ | https://documents1.worldbank.org/curated/en/442521523465644318/pdf/WPS8402.pdf | https://freopp.org/whitepapers/establishing-a-practical-return-on-investment-framework-for-education-and-skills-development-to-expand-economic-opportunity/
Infrastructure fiscal multiplier: 1.6 during contractionary phase of economic cycle Average across all economic states: 1.5 (meaning $1 of public investment → $1.50 of economic activity) Time horizon: 0.8 within 1 year, 1.5 within 2-5 years Range of estimates: 1.5-2.0 (following 2008 financial crisis & American Recovery Act) Italian public construction: 1.5-1.9 multiplier US ARRA: 0.4-2.2 range (differential impacts by program type) Economic Policy Institute: Uses 1.6 for infrastructure spending (middle range of estimates) Note: Public investment less likely to crowd out private activity during recessions; particularly effective when monetary policy loose with near-zero rates Additional sources: https://blogs.worldbank.org/en/ppps/effectiveness-infrastructure-investment-fiscal-stimulus-what-weve-learned | https://www.gihub.org/infrastructure-monitor/insights/fiscal-multiplier-effect-of-infrastructure-investment/ | https://cepr.org/voxeu/columns/government-investment-and-fiscal-stimulus | https://www.richmondfed.org/publications/research/economic_brief/2022/eb_22-04
Ramey (2011): 0.6 short-run multiplier Barro (1981): 0.6 multiplier for WWII spending (war spending crowded out 40¢ private economic activity per federal dollar) Barro & Redlick (2011): 0.4 within current year, 0.6 over two years; increased govt spending reduces private-sector GDP portions General finding: $1 increase in deficit-financed federal military spending = less than $1 increase in GDP Variation by context: Central/Eastern European NATO: 0.6 on impact, 1.5-1.6 in years 2-3, gradual fall to zero Ramey & Zubairy (2018): Cumulative 1% GDP increase in military expenditure raises GDP by 0.7% Additional sources: https://www.mercatus.org/research/research-papers/defense-spending-and-economy | https://cepr.org/voxeu/columns/world-war-ii-america-spending-deficits-multipliers-and-sacrifice | https://www.rand.org/content/dam/rand/pubs/research_reports/RRA700/RRA739-2/RAND_RRA739-2.pdf
The FDA GRAS (Generally Recognized as Safe) list contains approximately 570–700 substances. Additional sources: https://www.fda.gov/food/generally-recognized-safe-gras/gras-notice-inventory
2024: 233,597 deaths (30% increase from 179,099 in 2023) Deadliest conflicts: Ukraine (67,000), Palestine (35,000) Nearly 200,000 acts of violence (25% higher than 2023, double from 5 years ago) One in six people globally live in conflict-affected areas Additional sources: https://acleddata.com/2024/12/12/data-shows-global-conflict-surged-in-2024-the-washington-post/ | https://acleddata.com/media-citation/data-shows-global-conflict-surged-2024-washington-post | https://acleddata.com/conflict-index/index-january-2024/
.
54.
UCDP. State violence deaths annually. UCDP: Uppsala Conflict Data Programhttps://ucdp.uu.se/
Uppsala Conflict Data Program (UCDP): Tracks one-sided violence (organized actors attacking unarmed civilians) UCDP definition: Conflicts causing at least 25 battle-related deaths in calendar year 2023 total organized violence: 154,000 deaths; Non-state conflicts: 20,900 deaths UCDP collects data on state-based conflicts, non-state conflicts, and one-sided violence Specific "2,700 annually" figure for state violence not found in recent UCDP data; actual figures vary annually Additional sources: https://ucdp.uu.se/ | https://en.wikipedia.org/wiki/Uppsala_Conflict_Data_Program | https://ourworldindata.org/grapher/deaths-in-armed-conflicts-by-region
2023: 8,352 deaths (22% increase from 2022, highest since 2017) 2023: 3,350 terrorist incidents (22% decrease), but 56% increase in avg deaths per attack Global Terrorism Database (GTD): 200,000+ terrorist attacks recorded (2021 version) Maintained by: National Consortium for Study of Terrorism & Responses to Terrorism (START), U. of Maryland Geographic shift: Epicenter moved from Middle East to Central Sahel (sub-Saharan Africa) - now >50% of all deaths Additional sources: https://ourworldindata.org/terrorism | https://reliefweb.int/report/world/global-terrorism-index-2024 | https://www.start.umd.edu/gtd/ | https://ourworldindata.org/grapher/fatalities-from-terrorism
.
56.
Institute for Health Metrics and Evaluation (IHME). IHME global burden of disease 2021 (2.88B DALYs, 1.13B YLD). Institute for Health Metrics and Evaluation (IHME)https://vizhub.healthdata.org/gbd-results/ (2024)
In 2021, global DALYs totaled approximately 2.88 billion, comprising 1.75 billion Years of Life Lost (YLL) and 1.13 billion Years Lived with Disability (YLD). This represents a 13% increase from 2019 (2.55B DALYs), largely attributable to COVID-19 deaths and aging populations. YLD accounts for approximately 39% of total DALYs, reflecting the substantial burden of non-fatal chronic conditions. Additional sources: https://vizhub.healthdata.org/gbd-results/ | https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(24)00757-8/fulltext | https://www.healthdata.org/research-analysis/about-gbd
War on Terror emissions: 1.2B metric tons GHG (equivalent to 257M cars/year) Military: 5.5% of global GHG emissions (2X aviation + shipping combined) US DoD: World’s single largest institutional oil consumer, 47th largest emitter if nation Cleanup costs: $500B+ for military contaminated sites Gaza war environmental damage: $56.4B; landmine clearance: $34.6B expected Climate finance gap: Rich nations spend 30X more on military than climate finance Note: Military activities cause massive environmental damage through GHG emissions, toxic contamination, and long-term cleanup costs far exceeding current climate finance commitments Additional sources: https://watson.brown.edu/costsofwar/costs/social/environment | https://earth.org/environmental-costs-of-wars/ | https://transformdefence.org/transformdefence/stats/
Global military spending: $2.7 trillion (2024, SIPRI) Global government medical research: $68 billion (2024) Actual ratio: 39.7:1 in favor of weapons over medical research Military R&D alone: $85B (2004 data, 10% of global R&D) Military spending increases crowd out health: 1% ↑ military = 0.62% ↓ health spending Note: Ratio actually worse than 36:1. Each 1% increase in military spending reduces health spending by 0.62%, with effect more intense in poorer countries (0.962% reduction) Additional sources: https://www.sipri.org/commentary/blog/2016/opportunity-cost-world-military-spending | https://pmc.ncbi.nlm.nih.gov/articles/PMC9174441/ | https://www.congress.gov/crs-product/R45403
Lost human capital from war: $300B annually (economic impact of losing skilled/productive individuals to conflict) Broader conflict/violence cost: $14T/year globally 1.4M violent deaths/year; conflict holds back economic development, causes instability, widens inequality, erodes human capital 2002: 48.4M DALYs lost from 1.6M violence deaths = $151B economic value (2000 USD) Economic toll includes: commodity prices, inflation, supply chain disruption, declining output, lost human capital Additional sources: https://thinkbynumbers.org/military/war/the-economic-case-for-peace-a-comprehensive-financial-analysis/ | https://www.weforum.org/stories/2021/02/war-violence-costs-each-human-5-a-day/ | https://pubmed.ncbi.nlm.nih.gov/19115548/
PTSD economic burden (2018 U.S.): $232.2B total ($189.5B civilian, $42.7B military) Civilian costs driven by: Direct healthcare ($66B), unemployment ($42.7B) Military costs driven by: Disability ($17.8B), direct healthcare ($10.1B) Exceeds costs of other mental health conditions (anxiety, depression) War-exposed populations: 2-3X higher rates of anxiety, depression, PTSD; women and children most vulnerable Note: Actual burden $232B, significantly higher than "$100B" claimed Additional sources: https://pubmed.ncbi.nlm.nih.gov/35485933/ | https://news.va.gov/103611/study-national-economic-burden-of-ptsd-staggering/ | https://pmc.ncbi.nlm.nih.gov/articles/PMC9957523/
The average cost of supporting a refugee is $1,384 per year. This represents total host country costs (housing, healthcare, education, security). OECD countries average $6,100 per refugee (mean 2022-2023), with developing countries spending $700-1,000. Global weighted average of $1,384 is reasonable given that 75-85% of refugees are in low/middle-income countries. Additional sources: https://www.cgdev.org/blog/costs-hosting-refugees-oecd-countries-and-why-uk-outlier | https://www.unhcr.org/sites/default/files/2024-11/UNHCR-WB-global-cost-of-refugee-inclusion-in-host-country-health-systems.pdf
Estimated $616B annual cost from conflict-related trade disruption. World Bank research shows civil war costs an average developing country 30 years of GDP growth, with 20 years needed for trade to return to pre-war levels. Trade disputes analysis shows tariff escalation could reduce global exports by up to $674 billion. Additional sources: https://www.worldbank.org/en/topic/trade/publication/trading-away-from-conflict | https://www.nber.org/papers/w11565 | http://blogs.worldbank.org/en/trade/impacts-global-trade-and-income-current-trade-disputes
Global days of therapy reached 1.8 trillion in 2019 (234 defined daily doses per person). Diabetes, respiratory, CVD, and cancer account for 71 percent of medicine use. Projected to reach 3.8 trillion DDDs by 2028.
Estimated private pharmaceutical and biotech clinical trial spending is approximately $75-90 billion annually, representing roughly 90% of global clinical trial spending.
Global cybercrime costs: $3T (2015) → $6T (2021) → $10.5T (2025 projected) 15% annual growth rate If measured as country, would be 3rd largest economy after US and China Greatest transfer of economic wealth in history Note: More profitable than global trade of all major illegal drugs combined. Includes data theft, productivity loss, IP theft, fraud Additional sources: <https://cybersecurityventures.com/hackerpocalypse-cybercrime-report-2016/> | https://www.boisestate.edu/cybersecurity/2022/06/16/cybercrime-to-cost-the-world-10-5-trillion-annually-by-2025/
Quantifying the gap between current global governance and theoretical maximum welfare, estimating a 31-53% efficiency score and $97 trillion in annual opportunity costs.
Historical GDP per capita estimates from year 1 to present. Global GDP per capita in 1900: approximately 1,260 in 1990 international dollars (roughly 3,150 in 2024 USD after PPP and inflation adjustment). Standard reference for long-run comparative economic history.
Estimated range based on NIH ( $0.8-5.6B), NIHR ($1.6B total budget), and EU funding ( $1.3B/year). Roughly 5-10% of global market. Additional sources: https://www.appliedclinicaltrialsonline.com/view/sizing-clinical-research-market | https://www.thelancet.com/journals/langlo/article/PIIS2214-109X(20)30357-0/fulltext
Total global household wealth: USD 454.4 trillion (2022) Wealth declined by USD 11.3 trillion (-2.4%) in 2022, first decline since 2008 Wealth per adult: USD 84,718 Additional sources: https://www.ubs.com/global/en/family-office-uhnw/reports/global-wealth-report-2023.html
The 2024 Revision of the World Population Prospects provides population estimates and projections for 237 countries or areas. Global median age approximately 30.5 years in 2024, reflecting population-weighted average across all regions.
Estimated from major foundation budgets and activities. Nonprofit clinical trial funding estimate.
Nonprofit foundations spend an estimated $2-5 billion annually on clinical trials globally, representing approximately 2-5% of total clinical trial spending.
2024: >$100 billion ($190,151/minute) - 11% increase ($9.9B) from 2023 Nine nuclear-armed states: China, France, India, Israel, N. Korea, Pakistan, Russia, UK, US US: $56.8B (more than all other 8 states combined); China: $12.5B; UK: $10B (+26% YoY, biggest increase) Historical trend: $72.9B (2019) → $82.4B (2021) → >$100B (2024) Private sector contracts: $463B ongoing; $42.5B earned from contracts in 2024 alone Note: $100B/year figure accurate for 2024. Rapid growth from $73B (2019). US spends more than rest of world combined on nuclear weapons Additional sources: https://www.icanw.org/global_spending_on_nuclear_weapons_topped_100_billion_in_2024 | https://www.icanw.org/the_cost_of_nuclear_weapons
.
80.
Industry reports: IQVIA. Global pharmaceutical r&d spending.
Total global pharmaceutical R&D spending is approximately $300 billion annually. Clinical trials represent 15-20% of this total ($45-60B), with the remainder going to drug discovery, preclinical research, regulatory affairs, and manufacturing development.
Milestone: November 15, 2022 (UN World Population Prospects 2022) Day of Eight Billion" designated by UN Added 1 billion people in just 11 years (2011-2022) Growth rate: Slowest since 1950; fell under 1% in 2020 Future: 15 years to reach 9B (2037); projected peak 10.4B in 2080s Projections: 8.5B (2030), 9.7B (2050), 10.4B (2080-2100 plateau) Note: Milestone reached Nov 2022. Population growth slowing; will take longer to add next billion (15 years vs 11 years) Additional sources: https://www.un.org/en/desa/world-population-reach-8-billion-15-november-2022 | https://www.un.org/en/dayof8billion | https://en.wikipedia.org/wiki/Day_of_Eight_Billion
The research found that nonviolent campaigns were twice as likely to succeed as violent ones, and once 3.5% of the population were involved, they were always successful. Chenoweth and Maria Stephan studied the success rates of civil resistance efforts from 1900 to 2006, finding that nonviolent movements attracted, on average, four times as many participants as violent movements and were more likely to succeed. Key finding: Every campaign that mobilized at least 3.5% of the population in sustained protest was successful (in their 1900-2006 dataset) Note: The 3.5% figure is a descriptive statistic from historical analysis, not a guaranteed threshold. One exception (Bahrain 2011-2014 with 6%+ participation) has been identified. The rule applies to regime change, not policy change in democracies. Additional sources: https://www.hks.harvard.edu/centers/carr/publications/35-rule-how-small-minority-can-change-world | https://www.hks.harvard.edu/sites/default/files/2024-05/Erica%20Chenoweth_2020-005.pdf | https://www.bbc.com/future/article/20190513-it-only-takes-35-of-people-to-change-the-world | https://en.wikipedia.org/wiki/3.5%25_rule
Best current register-based estimate of global registered voters. Sum of the latest available country-level Registration counts in International IDEA’s world export on 2026-04-22 = 4,128,142,495 registered voters across 199 countries and political entities. Methodology notes that Registration is the number of names on the voters’ register as reported by electoral management bodies, and comparability is imperfect because voter rolls and registration systems differ across countries. Additional sources: https://www.idea.int/data-tools/data/voter-turnout-database | https://www.idea.int/data-tools/export?type=region_only&themeId=293&world=all&loc=home
As of early 2025, we estimate that the world’s nine nuclear-armed states possess a combined total of approximately 12,241 nuclear warheads. Additional sources: https://fas.org/issues/nuclear-weapons/status-world-nuclear-forces/
Sector ranks and per-company federal lobbying spending for 2025. Combined market capitalization of the top-5 publicly traded US lobbying spenders in each government-controlling sector: pharmaceuticals $1,794.7B; technology $13,279.5B; insurance $385.6B; oil and gas $1,246.9B; four-sector total approx $16.71T. Caveats: Meta (Zuckerberg holds 60.8% of voting power) and Alphabet (Page and Brin hold 52.3%) cannot be majority-acquired; Ellison owns 40.6% of Oracle; the largest insurance lobbyists are mutuals with no public shares; trade associations (PhRMA, AHIP, SIFMA, API) are not acquirable. Additional sources: https://stockanalysis.com/stocks/
Your DNA is 3 billion base pairs Read the entire code (Human Genome Project, completed 2003) Learned to edit it (CRISPR, discovered 2012) Additional sources: https://www.genome.gov/11006929/2003-release-international-consortium-completes-hgp | https://www.nobelprize.org/prizes/chemistry/2020/press-release/
Mapping 350,000+ clinical trials showed that only 12% of the human interactome has ever been targeted by drugs. Additional sources: https://pmc.ncbi.nlm.nih.gov/articles/PMC10749231/
The ICD-10 classification contains approximately 14,000 codes for diseases, signs and symptoms. Additional sources: https://icd.who.int/browse10/2019/en
Leaded gasoline, used in the US from 1923 until its on-road ban in 1996, exposed more than half of the 2015 US population to adverse blood-lead levels in early childhood. The authors estimate childhood lead exposure cost the population a cumulative 824 million IQ points, an average of 2.6 points per person, rising to 5.9 points for the most-exposed 1966-1970 birth cohort.
Longevity escape velocity: Hypothetical point where medical advances extend life expectancy faster than time passes Term coined by Aubrey de Grey (biogerontologist) in 2004 paper; concept from David Gobel (Methuselah Foundation) Current progress: Science adds 3 months to lifespan per year; LEV requires adding >1 year per year Sinclair (Harvard): "There is no biological upper limit to age" - first person to live to 150 may already be born De Grey: 50% chance of reaching LEV by mid-to-late 2030s; SENS approach = damage repair rather than slowing damage Kurzweil (2024): LEV by 2029-2035, AI will simulate biological processes to accelerate solutions George Church: LEV "in a decade or two" via age-reversal clinical trials Natural lifespan cap: 120-150 years (Jeanne Calment record: 122); engineering approach could bypass via damage repair Key mechanisms: Epigenetic reprogramming, senolytic drugs, stem cell therapy, gene therapy, AI-driven drug discovery Current record: Jeanne Calment (122 years, 164 days) - record unbroken since 1997 Note: LEV is theoretical but increasingly plausible given demonstrated age reversal in mice (109% lifespan extension) and human cells (30-year epigenetic age reversal) Additional sources: https://en.wikipedia.org/wiki/Longevity_escape_velocity | https://pmc.ncbi.nlm.nih.gov/articles/PMC423155/ | https://www.popularmechanics.com/science/a36712084/can-science-cure-death-longevity/ | https://www.diamandis.com/blog/longevity-escape-velocity
Registered lobbyists: Over 12,000 (some estimates); 12,281 registered (2013) Former government employees as lobbyists: 2,200+ former federal employees (1998-2004), including 273 former White House staffers, 250 former Congress members & agency heads Congressional revolving door: 43% (86 of 198) lawmakers who left 1998-2004 became lobbyists; currently 59% leaving to private sector work for lobbying/consulting firms/trade groups Executive branch: 8% were registered lobbyists at some point before/after government service Additional sources: https://en.wikipedia.org/wiki/Lobbying_in_the_United_States | https://www.opensecrets.org/revolving-door | https://www.citizen.org/article/revolving-congress/ | https://www.propublica.org/article/we-found-a-staggering-281-lobbyists-whove-worked-in-the-trump-administration
Single measles vaccination: 167:1 benefit-cost ratio. MMR (measles-mumps-rubella) vaccination: 14:1 ROI. Historical US elimination efforts (1966-1974): benefit-cost ratio of 10.3:1 with net benefits exceeding USD 1.1 billion (1972 dollars, or USD 8.0 billion in 2023 dollars). 2-dose MMR programs show direct benefit/cost ratio of 14.2 with net savings of $5.3 billion, and 26.0 from societal perspectives with net savings of $11.6 billion. Additional sources: https://www.mdpi.com/2076-393X/12/11/1210 | https://www.tandfonline.com/doi/full/10.1080/14760584.2024.2367451
U.S. Government Accountability Office. Electronic Health Records: First Year of CMS’s Incentive Programs Shows Opportunities to Improve Processes to Verify Providers Met Requirements. https://www.gao.gov/products/gao-12-481 (2012).
One in four people in the world will be affected by mental or neurological disorders at some point in their lives, representing [approximately] 30% of the global burden of disease. Additional sources: https://www.who.int/news/item/28-09-2001-the-world-health-report-2001-mental-disorders-affect-one-in-four-people
IQ was significant at the 95% level in 99.8% of 1,330 BACE growth regressions. A 1 point increase in a nation’s average IQ is associated with a persistent 0.11% annual increase in GDP per capita.
Under the current system, approximately 10-15 diseases per year receive their FIRST effective treatment. Calculation: 5% of 7,000 rare diseases ( 350) have FDA-approved treatment, accumulated over 40 years of the Orphan Drug Act = 9 rare diseases/year. Adding 5-10 non-rare diseases that get first treatments yields 10-20 total. FDA approves 50 drugs/year, but many are for diseases that already have treatments (me-too drugs, second-line therapies). Only 15 represent truly FIRST treatments for previously untreatable conditions.
The budget total of $47.7 billion also includes $1.412 billion derived from PHS Evaluation financing... Additional sources: https://www.nih.gov/about-nih/organization/budget | https://officeofbudget.od.nih.gov/
Typical cost-effectiveness thresholds for medical interventions in rich countries range from $50,000 to $150,000 per QALY. The Institute for Clinical and Economic Review (ICER) uses a $100,000-$150,000/QALY threshold for value-based pricing. Between 1990-2021, authors increasingly cited $100,000 (47% by 2020-21) or $150,000 (24% by 2020-21) per QALY as benchmarks for cost-effectiveness. Additional sources: https://pmc.ncbi.nlm.nih.gov/articles/PMC10114019/ | https://icer.org/our-approach/methods-process/cost-effectiveness-the-qaly-and-the-evlyg/
We estimate that a nuclear war between the United States and Russia would produce 150 Tg of soot and lead to 5 billion people dying at the end of year 2. Additional sources: https://www.nature.com/articles/s43016-022-00573-0
Recent surveys: 49-51% willingness (2020-2022) - dramatic drop from 85% (2019) during COVID-19 pandemic Cancer patients when approached: 88% consented to trials (Royal Marsden Hospital) Study type variation: 44.8% willing for drug trial, 76.2% for diagnostic study Top motivation: "Learning more about my health/medical condition" (67.4%) Top barrier: "Worry about experiencing side effects" (52.6%) Additional sources: https://trialsjournal.biomedcentral.com/articles/10.1186/s13063-015-1105-3 | https://www.appliedclinicaltrialsonline.com/view/industry-forced-to-rethink-patient-participation-in-trials | https://pmc.ncbi.nlm.nih.gov/articles/PMC7183682/
In the most recent audit, the Department of Defense (DoD) could not account for approximately 60% of its \(4.1 trillion in assets, amounting to\)2.46 trillion unaccounted for. Alternative title: Pentagon unsupported accounting adjustments (\(6.5T, single year, US Army) In 2015, the Department of Defense's Inspector General reported that the Army could not adequately support\)6.5 trillion in year-end adjustments, indicating severe accounting discrepancies. Additional sources: https://thecommunemag.com/the-pentagon-misplaced-2-46-trillion-an-in-depth-look-at-the-financial-audit-failures | https://accmag.com/audit-pentagon-cannot-account-for-6-5-trillion-dollars-is-taxpayer-money/
.
114.
Tufts CSDD. Cost of drug development.
Various estimates suggest $1.0 - $2.5 billion to bring a new drug from discovery through FDA approval, spread across 10 years. Tufts Center for the Study of Drug Development often cited for $1.0 - $2.6 billion/drug. Industry reports (IQVIA, Deloitte) also highlight $2+ billion figures.
Study of 361 FDA-approved drugs from 1995-2014 (median follow-up 13.2 years): Mean lifetime revenue: $15.2 billion per drug Median lifetime revenue: $6.7 billion per drug Revenue after 5 years: $3.2 billion (mean) Revenue after 10 years: $9.5 billion (mean) Revenue after 15 years: $19.2 billion (mean) Distribution highly skewed: top 25 drugs (7%) accounted for 38% of total revenue ($2.1T of $5.5T) Additional sources: https://www.sciencedirect.com/science/article/pii/S1098301524027542
Using 3-way fixed-effects methodology (disease-country-year) across 66 diseases in 22 countries, this study estimates that drugs launched after 1981 saved 148.7 million life-years in 2013 alone. The regression coefficients for drug launches 0-11 years prior (beta=-0.031, SE=0.008) and 12+ years prior (beta=-0.057, SE=0.013) on years of life lost are highly significant (p<0.0001). Confidence interval for life-years saved: 79.4M-239.8M (95 percent CI) based on propagated standard errors from Table 2.
Deloitte’s annual study of top 20 pharma companies by R&D spend (2010-2024): 2024 ROI: 5.9% (second year of growth after decade of decline) 2023 ROI: 4.3% (estimated from trend) 2022 ROI: 1.2% (historic low since study began, 13-year low) 2021 ROI: 6.8% (record high, inflated by COVID-19 vaccines/treatments) Long-term trend: Declining for over a decade before 2023 recovery Average R&D cost per asset: $2.3B (2022), $2.23B (2024) These returns (1.2-5.9% range) fall far below typical corporate ROI targets (15-20%) Additional sources: https://www.deloitte.com/ch/en/Industries/life-sciences-health-care/research/measuring-return-from-pharmaceutical-innovation.html | https://www.prnewswire.com/news-releases/deloittes-13th-annual-pharmaceutical-innovation-report-pharma-rd-return-on-investment-falls-in-post-pandemic-market-301738807.html | https://hitconsultant.net/2023/02/16/pharma-rd-roi-falls-to-lowest-level-in-13-years/
.
118.
Nature Reviews Drug Discovery. Drug trial success rate from phase i to approval. Nature Reviews Drug Discovery: Clinical Success Rateshttps://www.nature.com/articles/nrd.2016.136 (2016)
Overall Phase I to approval: 10-12.8% (conventional wisdom 10%, studies show 12.8%) Recent decline: Average LOA now 6.7% for Phase I (2014-2023 data) Leading pharma companies: 14.3% average LOA (range 8-23%) Varies by therapeutic area: Oncology 3.4%, CNS/cardiovascular lowest at Phase III Phase-specific success: Phase I 47-54%, Phase II 28-34%, Phase III 55-70% Note: 12% figure accurate for historical average. Recent data shows decline to 6.7%, with Phase II as primary attrition point (28% success) Additional sources: https://www.nature.com/articles/nrd.2016.136 | https://pmc.ncbi.nlm.nih.gov/articles/PMC6409418/ | https://academic.oup.com/biostatistics/article/20/2/273/4817524
Phase 3 clinical trials cost between $20 million and $282 million per trial, with significant variation by therapeutic area and trial complexity. Additional sources: https://www.sofpromed.com/how-much-does-a-clinical-trial-cost | https://www.cbo.gov/publication/57126
Meta-analysis of 108 embedded pragmatic clinical trials (2006-2016). The median cost per patient was $97 (IQR $19–$478), based on 2015 dollars. 25% of trials cost <$19/patient; 10 trials exceeded $1,000/patient. U.S. studies median $187 vs non-U.S. median $27. Additional sources: https://pmc.ncbi.nlm.nih.gov/articles/PMC6508852/
For every dollar spent, the return on investment is nearly US$ 39." Total investment cost of US$ 7.5 billion generates projected economic and social benefits of US$ 289.2 billion from sustaining polio assets and integrating them into expanded immunization, surveillance and emergency response programmes across 8 priority countries (Afghanistan, Iraq, Libya, Pakistan, Somalia, Sudan, Syria, Yemen). Additional sources: https://www.who.int/news-room/feature-stories/detail/sustaining-polio-investments-offers-a-high-return
ICBL: Founded 1992 by 6 NGOs (Handicap International, Human Rights Watch, Medico International, Mines Advisory Group, Physicians for Human Rights, Vietnam Veterans of America Foundation) Started with ONE staff member: Jody Williams as founding coordinator Grew to 1,000+ organizations in 60 countries by 1997 Ottawa Process: 14 months (October 1996 - December 1997) Convention signed by 122 states on December 3, 1997; entered into force March 1, 1999 Achievement: Nobel Peace Prize 1997 (shared by ICBL and Jody Williams) Government funding context: Canada established $100M CAD Canadian Landmine Fund over 10 years (1997); International donors provided $169M in 1997 for mine action (up from $100M in 1996) Additional sources: https://www.icrc.org/en/doc/resources/documents/article/other/57jpjn.htm | https://en.wikipedia.org/wiki/International_Campaign_to_Ban_Landmines | https://www.nobelprize.org/prizes/peace/1997/summary/ | https://un.org/press/en/1999/19990520.MINES.BRF.html | https://www.the-monitor.org/en-gb/reports/2003/landmine-monitor-2003/mine-action-funding.aspx
388 former members of Congress are registered as lobbyists. Nearly 5,400 former congressional staffers have left Capitol Hill to become federal lobbyists in the past 10 years. Additional sources: https://www.opensecrets.org/revolving-door
Research identified 1,600+ medicines available in 1962. The 1950s represented industry high-water mark with >30 new products in five of ten years; this rate would not be replicated until late 1990s. More than half (880) of these medicines were lost following implementation of Kefauver-Harris Amendment. The peak of 1962 would not be seen again until early 21st century. By 2016 number of organizations actively involved in R&D at level not seen since 1914.
Pre-1962: Average cost per new chemical entity (NCE) was $6.5 million (1980 dollars) Inflation-adjusted to 2024 dollars: $6.5M (1980) ≈ $22.5M (2024), using CPI multiplier of 3.46× Real cost increase (inflation-adjusted): $22.5M (pre-1962) → $2,600M (2024) = 116× increase Note: This represents the most comprehensive academic estimate of pre-1962 drug development costs based on empirical industry data Additional sources: https://samizdathealth.org/wp-content/uploads/2020/12/hlthaff.1.2.6.pdf
Pre-1962: Physicians could report real-world evidence directly 1962 Drug Amendments replaced "premarket notification" with "premarket approval", requiring extensive efficacy testing Impact: New regulatory clampdown reduced new treatment production by 70%; lifespan growth declined from 4 years/decade to 2 years/decade Drug Efficacy Study Implementation (DESI): NAS/NRC evaluated 3,400+ drugs approved 1938-1962 for safety only; reviewed >3,000 products, >16,000 therapeutic claims FDA has had authority to accept real-world evidence since 1962, clarified by 21st Century Cures Act (2016) Note: Specific "144,000 physicians" figure not verified in sources Additional sources: https://thinkbynumbers.org/health/how-many-net-lives-does-the-fda-save/ | https://www.fda.gov/drugs/enforcement-activities-fda/drug-efficacy-study-implementation-desi | http://www.nasonline.org/about-nas/history/archives/collections/des-1966-1969-1.html
The RECOVERY trial, for example, cost only about $500 per patient... By contrast, the median per-patient cost of a pivotal trial for a new therapeutic is around $41,000. Additional sources: https://manhattan.institute/article/slow-costly-clinical-trials-drag-down-biomedical-breakthroughs
Dexamethasone saved 1 million lives worldwide (NHS England estimate, March 2021, 9 months after discovery). UK alone: 22,000 lives saved. Methodology: Águas et al. Nature Communications 2021 estimated 650,000 lives (range: 240,000-1,400,000) for July-December 2020 alone, based on RECOVERY trial mortality reductions (36% for ventilated, 18% for oxygen-only patients) applied to global COVID hospitalizations. June 2020 announcement: Dexamethasone reduced deaths by up to 1/3 (ventilated patients), 1/5 (oxygen patients). Impact immediate: Adopted into standard care globally within hours of announcement. Additional sources: https://www.england.nhs.uk/2021/03/covid-treatment-developed-in-the-nhs-saves-a-million-lives/ | https://www.nature.com/articles/s41467-021-21134-2 | https://pharmaceutical-journal.com/article/news/steroid-has-saved-the-lives-of-one-million-covid-19-patients-worldwide-figures-show | https://www.recoverytrial.net/news/recovery-trial-celebrates-two-year-anniversary-of-life-saving-dexamethasone-result
2,977 people were killed in the September 11, 2001 attacks: 2,753 at the World Trade Center, 184 at the Pentagon, and 40 passengers and crew on United Flight 93 in Shanksville, Pennsylvania.
Singapore GDP per capita (2023): $82,000 - among highest in the world Government spending: 15% of GDP (vs US 38%) Life expectancy: 84.1 years (vs US 77.5 years) Singapore demonstrates that low government spending can coexist with excellent outcomes Additional sources: https://data.worldbank.org/country/singapore
Singapore government spending is approximately 15% of GDP This is 23 percentage points lower than the United States (38%) Despite lower spending, Singapore achieves excellent outcomes: - Life expectancy: 84.1 years (vs US 77.5) - Low crime, world-class infrastructure, AAA credit rating Additional sources: https://www.imf.org/en/Countries/SGP
Life expectancy at birth varies significantly among developed nations: Switzerland: 84.0 years (2023) Singapore: 84.1 years (2023) Japan: 84.3 years (2023) United States: 77.5 years (2023) - 6.5 years below Switzerland, Singapore Global average: 73 years Note: US spends more per capita on healthcare than any other nation, yet achieves lower life expectancy Additional sources: https://www.who.int/data/gho/data/themes/mortality-and-global-health-estimates/ghe-life-expectancy-and-healthy-life-expectancy
Population-level: Up to 14% (9% men, 14% women) of total life expectancy gain since 1960 due to tobacco control efforts Individual cessation benefits: Quitting at age 35 adds 6.9-8.5 years (men), 6.1-7.7 years (women) vs continuing smokers By cessation age: Age 25-34 = 10 years gained; age 35-44 = 9 years; age 45-54 = 6 years; age 65 = 2.0 years (men), 3.7 years (women) Cessation before age 40: Reduces death risk by 90% Long-term cessation: 10+ years yields survival comparable to never smokers, averts 10 years of life lost Recent cessation: <3 years averts 5 years of life lost Additional sources: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1447499/ | https://www.cdc.gov/pcd/issues/2012/11_0295.htm | https://www.ajpmonline.org/article/S0749-3797(24)00217-4/fulltext | https://www.nejm.org/doi/full/10.1056/NEJMsa1211128
Standard economic value per QALY: $100,000–$150,000. This is the US and global standard willingness-to-pay threshold for interventions that add costs. Dominant interventions (those that save money while improving health) are favorable regardless of this threshold. Additional sources: https://icer.org/wp-content/uploads/2024/02/Reference-Case-4.3.25.pdf
Consumer costs: $2.5-3.5 billion per year (GAO estimate) Net economic cost: $1 billion per year 2022: US consumers paid 2X world price for sugar Program costs $3-4 billion/year but no federal budget impact (costs passed directly to consumers via higher prices) Employment impact: 10,000-20,000 manufacturing jobs lost annually in sugar-reliant industries (confectionery, etc.) Multiple studies confirm: Sweetener Users Association ($2.9-3.5B), AEI ($2.4B consumer cost), Beghin & Elobeid ($2.9-3.5B consumer surplus) Additional sources: https://www.gao.gov/products/gao-24-106144 | https://www.heritage.org/agriculture/report/the-us-sugar-program-bad-consumers-bad-agriculture-and-bad-america | https://www.aei.org/articles/the-u-s-spends-4-billion-a-year-subsidizing-stalinist-style-domestic-sugar-production/
2023: 0.70272% of GDP (World Bank) 2024: CHF 5.95 billion official military spending When including militia system costs: 1% GDP (CHF 8.75B) Comparison: Near bottom in Europe; only Ireland, Malta, Moldova spend less (excluding microstates with no armies) Additional sources: https://data.worldbank.org/indicator/MS.MIL.XPND.GD.ZS?locations=CH | https://www.avenir-suisse.ch/en/blog-defence-spending-switzerland-is-in-better-shape-than-it-seems/ | https://tradingeconomics.com/switzerland/military-expenditure-percent-of-gdp-wb-data.html
2024 GDP per capita (PPP-adjusted): Switzerland $93,819 vs United States $75,492 Switzerland’s GDP per capita 24% higher than US when adjusted for purchasing power parity Nominal 2024: Switzerland $103,670 vs US $85,810 Additional sources: https://data.worldbank.org/indicator/NY.GDP.PCAP.CD?locations=CH | https://tradingeconomics.com/switzerland/gdp-per-capita-ppp | https://www.theglobaleconomy.com/USA/gdp_per_capita_ppp/
OECD government spending data shows significant variation among developed nations: United States: 38.0% of GDP (2023) Switzerland: 35.0% of GDP - 3 percentage points lower than US Singapore: 15.0% of GDP - 23 percentage points lower than US (per IMF data) OECD average: approximately 40% of GDP Additional sources: https://data.oecd.org/gga/general-government-spending.htm
The total number of embryos affected by the use of thalidomide during pregnancy is estimated at 10,000, of whom about 40% died around the time of birth. More than 10,000 children in 46 countries were born with deformities such as phocomelia. Additional sources: https://en.wikipedia.org/wiki/Thalidomide_scandal
Study of thalidomide survivors documenting ongoing disability impacts, quality of life, and long-term health outcomes. Survivors (now in their 60s) continue to experience significant disability from limb deformities, organ damage, and other effects. Additional sources: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0210222
US Census Bureau historical estimates of world population by country and region (1950-2050). US population in 1960: 180 million of 3 billion worldwide (6%). Additional sources: https://www.census.gov/data/tables/time-series/demo/international-programs/historical-est-worldpop.html
Overall, the 138 clinical trials had an estimated median (IQR) cost of $19.0 million ($12.2 million-$33.1 million)... The clinical trials cost a median (IQR) of $41,117 ($31,802-$82,362) per patient. Additional sources: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6248200/
Disability weights for 235 health states used in Global Burden of Disease calculations. Weights range from 0 (perfect health) to 1 (death equivalent). Chronic conditions like diabetes (0.05-0.35), COPD (0.04-0.41), depression (0.15-0.66), and cardiovascular disease (0.04-0.57) show substantial variation by severity. Treatment typically reduces disability weights by 50-80 percent for manageable chronic conditions.
Chronic diseases account for 90% of U.S. healthcare spending ( $3.7T/year). Additional sources: https://www.cdc.gov/chronic-disease/data-research/facts-stats/index.html
US GDP reached $28.78 trillion in 2024, representing approximately 26% of global GDP. Additional sources: https://data.worldbank.org/indicator/NY.GDP.MKTP.CD?locations=US | https://www.bea.gov/news/2024/gross-domestic-product-fourth-quarter-and-year-2024-advance-estimate
.
155.
Environmental Working Group. US farm subsidy database and analysis. Environmental Working Grouphttps://farm.ewg.org/ (2024)
US agricultural subsidies total approximately $30 billion annually, but create much larger economic distortions. Top 10% of farms receive 78% of subsidies, benefits concentrated in commodity crops (corn, soy, wheat, cotton), environmental damage from monoculture incentivized, and overall deadweight loss estimated at $50-120 billion annually. Additional sources: https://farm.ewg.org/ | https://www.ers.usda.gov/topics/farm-economy/farm-sector-income-finances/government-payments-the-safety-net/
Since 1971, the war on drugs has cost the United States an estimated $1 trillion in enforcement. The federal drug control budget was $41 billion in 2022. Mass incarceration costs the U.S. at least $182 billion every year, with over $450 billion spent to incarcerate individuals on drug charges in federal prisons.
Globally, fossil fuel subsidies were $7 trillion in 2022 or 7.1 percent of GDP. The United States subsidies totaled $649 billion. Underpricing for local air pollution costs and climate damages are the largest contributor, accounting for about 30 percent each.
The US spent approximately twice as much as other high-income countries on medical care (mean per capita: $9,892 vs $5,289), with similar utilization but much higher prices. Administrative costs accounted for 8% of US spending vs 1-3% in other countries. US spending on pharmaceuticals was $1,443 per capita vs $749 elsewhere. Despite spending more, US health outcomes are not better. Additional sources: https://jamanetwork.com/journals/jama/article-abstract/2674671
We quantify the amount of spatial misallocation of labor across US cities and its aggregate costs. Tight land-use restrictions in high-productivity cities like New York, San Francisco, and Boston lowered aggregate US growth by 36% from 1964 to 2009. Local constraints on housing supply have had enormous effects on the national economy. Additional sources: https://www.aeaweb.org/articles?id=10.1257/mac.20170388
Accounting for all the 2025 US tariffs and retaliation implemented to date, the level of real GDP is persistently -0.6% smaller in the long run, the equivalent of $160 billion 2024$ annually.
Americans will spend over 7.9 billion hours complying with IRS tax filing and reporting requirements in 2024. This costs the economy roughly $413 billion in lost productivity. In addition, the IRS estimates that Americans spend roughly $133 billion annually in out-of-pocket costs, bringing the total compliance costs to $546 billion, or nearly 2 percent of GDP.
Heart failure alone: $108 billion/year (2012 global analysis, 197 countries) US CVD: $555B (2016) → projected $1.8T by 2050 LMICs total CVD loss: $3.7T cumulative (2011-2015, 5-year period) CVD is costliest disease category in most developed nations Note: No single $2.1T global figure found; estimates vary widely by scope and year Additional sources: https://www.ahajournals.org/doi/10.1161/CIR.0000000000001258
US life expectancy at birth was 77.5 years in 2023 Male life expectancy: 74.8 years Female life expectancy: 80.2 years This is 6-7 years lower than peer developed nations despite higher healthcare spending Additional sources: https://www.cdc.gov/nchs/fastats/life-expectancy.htm
US median household income was $77,500 in 2023 Real median household income declined 0.8% from 2022 Gini index: 0.467 (income inequality measure) Additional sources: https://www.census.gov/library/publications/2024/demo/p60-282.html
US military spending in constant 2024 dollars: 1939 $29B (pre-WW2 baseline), 1940 $37B, 1944 $1,383B, 1945 $1,420B (peak), 1946 $674B, 1947 $176B, 1948 $117B, 2024 $886B. The post-WW2 demobilization cut spending 88% in two years (1945-1947). Current peacetime spending ($886B) is 30x the pre-WW2 baseline and 62% of peak WW2 spending, in inflation-adjusted dollars.
U.S. military spending amounted to 3.5% of GDP in 2024. In 2024, the U.S. spent nearly $1 trillion on its military budget, equal to 3.4% of GDP. Additional sources: https://www.statista.com/statistics/262742/countries-with-the-highest-military-spending/ | https://www.sipri.org/sites/default/files/2025-04/2504_fs_milex_2024.pdf
73.6% (or 174 million people) of the citizen voting-age population was registered to vote in 2024 (Census Bureau). More than 211 million citizens were active registered voters (86.6% of citizen voting age population) according to the Election Assistance Commission. Additional sources: https://www.census.gov/newsroom/press-releases/2025/2024-presidential-election-voting-registration-tables.html | https://www.eac.gov/news/2025/06/30/us-election-assistance-commission-releases-2024-election-administration-and-voting
The Constitution provides that the president ’shall have Power, by and with the Advice and Consent of the Senate, to make Treaties, provided two-thirds of the Senators present concur’ (Article II, section 2). Treaties are formal agreements with foreign nations that require two-thirds Senate approval. 67 senators (two-thirds of 100) must vote to ratify a treaty for it to take effect. Additional sources: https://www.senate.gov/about/powers-procedures/treaties.htm
Presidential candidates raised $2 billion; House and Senate candidates raised $3.8 billion and spent $3.7 billion; PACs raised $15.7 billion and spent $15.5 billion. Total federal campaign spending approximately $20 billion. Additional sources: https://www.fec.gov/updates/statistical-summary-of-24-month-campaign-activity-of-the-2023-2024-election-cycle/
Total federal lobbying reached record $4.4 billion in 2024. The $150 million increase in lobbying continues an upward trend that began in 2016. Additional sources: https://www.opensecrets.org/news/2025/02/federal-lobbying-set-new-record-in-2024/
National average: 1 in 60 million chance (2008 election analysis by Gelman, Silver, Edlin) Swing states (NM, VA, NH, CO): 1 in 10 million chance Non-competitive states: 34 states >1 in 100 million odds; 20 states >1 in 1 billion Washington DC: 1 in 490 billion odds Methodology: Probability state is necessary for electoral college win × probability state vote is tied Additional sources: https://sites.stat.columbia.edu/gelman/research/published/probdecisive2.pdf | https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1465-7295.2010.00272.x
The overall failure rate of drugs that passed into Phase 1 trials to final approval is 90%. This lack of translation from promising preclinical findings to success in human trials is known as the "valley of death." Estimated 30-50% of promising compounds never proceed to Phase 2/3 trials primarily due to funding barriers rather than scientific failure. The late-stage attrition rate for oncology drugs is as high as 70% in Phase II and 59% in Phase III trials.
Current VSL (2024): $13.7 million (updated from $13.6M) Used in cost-benefit analyses for transportation regulations and infrastructure Methodology updated in 2013 guidance, adjusted annually for inflation and real income VSL represents aggregate willingness to pay for safety improvements that reduce fatalities by one Note: DOT has published VSL guidance periodically since 1993. Current $13.7M reflects 2024 inflation/income adjustments Additional sources: https://www.transportation.gov/office-policy/transportation-policy/revised-departmental-guidance-on-valuation-of-a-statistical-life-in-economic-analysis | https://www.transportation.gov/regulations/economic-values-used-in-analysis
India: $23-$50 per DALY averted (least costly intervention, $1,000-$6,100 per death averted) Sub-Saharan Africa (2022): $220-$860 per DALY (Burkina Faso: $220, Kenya: $550, Nigeria: $860) WHO estimates for Africa: $40 per DALY for fortification, $255 for supplementation Uganda fortification: $18-$82 per DALY (oil: $18, sugar: $82) Note: Wide variation reflects differences in baseline VAD prevalence, coverage levels, and whether intervention is supplementation or fortification Additional sources: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0012046 | https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0266495
The $50,000/QALY threshold is widely used in US health economics literature, originating from dialysis cost benchmarks in the 1980s. In US cost-utility analyses, 77.5% of authors use either $50,000 or $100,000 per QALY as reference points. Most successful health programs cost $3,000-10,000 per QALY. WHO-CHOICE uses GDP per capita multiples (1× GDP/capita = "very cost-effective", 3× GDP/capita = "cost-effective"), which for the US ( $70,000 GDP/capita) translates to $70,000-$210,000/QALY thresholds. Additional sources: https://pmc.ncbi.nlm.nih.gov/articles/PMC5193154/ | https://pmc.ncbi.nlm.nih.gov/articles/PMC9278384/
78.4% of U.S. employees have at least one chronic condition (7% increase since 2021) 58% of employees report physical chronic health conditions 28% of all employees experience productivity loss due to chronic conditions Average productivity loss: $4,798 per employee per year Employees with 3+ chronic conditions miss 7.8 days annually vs 2.2 days for those without Note: 28% productivity loss translates to roughly 11 hours per week (28% of 40-hour workweek) Additional sources: https://www.ibiweb.org/resources/chronic-conditions-in-the-us-workforce-prevalence-trends-and-productivity-impacts | https://www.onemedical.com/mediacenter/study-finds-more-than-half-of-employees-are-living-with-chronic-conditions-including-1-in-3-gen-z-and-millennial-employees/ | https://debeaumont.org/news/2025/poll-the-toll-of-chronic-health-conditions-on-employees-and-workplaces/
The Optimal Policy Generator (OPG) produces systematic public policy recommendations for jurisdictions at any level (country, state, city), generating prioritized enact/replace/repeal/maintain recommendations to maximize real after-tax median income growth and median healthy life years, based on quasi-experimental evidence from centuries of policy variation data.
Government spending is optimized for lobbying intensity, not net societal value. Programs with 100:1 benefit-cost ratios get billions while programs with negative returns get hundreds of billions. Incentive Alignment Bonds flip this by creating a capital pool that rewards politicians (via campaign support and post-office opportunities) for funding high-NSV programs over low-NSV alternatives. The result: public good becomes private profit for both investors and elected officials.
Arrow’s Impossibility Theorem proves that no rank-order voting system can satisfy all of four "fairness" criteria: unrestricted domain, non-dictatorship, Pareto efficiency, and independence of irrelevant alternatives. This foundational result in social choice theory demonstrates that there is no perfect method for aggregating individual preferences into collective decisions—all voting systems involve tradeoffs. The theorem has profound implications for democratic theory, welfare economics, and mechanism design, showing that preference aggregation is irreducibly political. Additional sources: https://www.amazon.com/Social-Choice-Individual-Values-Monograph/dp/0300013647
.
185.
Myerson, R. B. Optimal auction design. Mathematics of Operations Research6, 58–73 (1981)
This seminal paper establishes the Revenue Equivalence Theorem and introduces the "virtual valuation" concept for mechanism design. Myerson shows how to design auctions that maximize expected revenue given incentive-compatible reporting constraints. The paper, along with the Revelation Principle, provides foundational tools for designing mechanisms where agents truthfully report private information. Essential for understanding incentive-compatible oracle design in algorithmic governance systems.
Time-inconsistency describes situations where, with the passing of time, policies that were determined to be optimal yesterday are no longer perceived to be optimal today and are not implemented... This insight shifted the focus of policy analysis from the study of individual policy decisions to the design of institutions that mitigate the time consistency problem.
The quality-adjusted life year (QALY) is the academic standard for measuring how well all different kinds of medical treatments lengthen and/or improve patients’ lives, and therefore the metric has served as a fundamental component of cost-effectiveness analyses in the US and around the world for more than 30 years. ICER’s health benefit price benchmark (HBPB) will continue to be reported using the standard range from $100,000 to $150,000 per QALY and per evLYG. Additional sources: https://icer.org/our-approach/methods-process/cost-effectiveness-the-qaly-and-the-evlyg/ | https://icer.org/wp-content/uploads/2024/02/Reference-Case-4.3.25.pdf
The primary engine driving improvement has been a focus on the quality of empirical research designs. Additional sources: https://www.aeaweb.org/articles?id=10.1257/jep.24.2.3
Using exogenous variation from court-ordered school finance reforms, finds that a 10% increase in per-pupil spending throughout all 12 years of public school leads to 0.31 more completed years of education, 7.25% higher wages, and a 3.67 percentage-point reduction in adult poverty. This is one of the most credible causal estimates of the effect of education spending on adult outcomes, using natural experiments to address reverse causality concerns.
Only 15 diseases/year get their first treatment each year. With 6.65 thousand diseases lacking effective treatments, the backlog would take 443 years to clear. Integrating pragmatic trials into standard healthcare increases trial capacity 12.3x, cutting that timeline from 443 years to 36 years. The average untreated disease gets a treatment 212 years earlier, saving 10.7 billion deaths at $0.842 per year of healthy life saved.
One trial. Over 47,000 participants. Nearly 200 hospital sites, across six countries. Ten results. Four effective COVID-19 treatments... Through discovering four treatments that effectively reduce deaths from COVID-19, it is certain that the study has saved thousands – if not millions – of lives worldwide. Additional sources: https://www.ox.ac.uk/news/features/recovery-trial-two-years
Meta-analysis of 34 evidence-based interventions for maternal and child health demonstrates that universal coverage with proven interventions could prevent 2.3 million neonatal deaths and 1.5 million child deaths annually. The benefit-cost ratios for these interventions consistently exceed 10:1.
Every $1 spent on childhood immunizations results in approximately $11 in savings (700% ROI). For low/middle-income countries: $26.1-$51.0 ROI using cost-of-illness approach, $52.2 ROI using value-of-statistical-life approach. US childhood vaccines 1994-2023 saved $540B in direct costs, $2.7T in total societal savings. Additional sources: https://www.americanactionforum.org/research/vaccine-protection-and-productivity-the-economic-value-of-vaccines/ | https://www.healthaffairs.org/doi/10.1377/hlthaff.2020.00103 | https://immunizationevidence.org/featured_issues/the-value-of-vaccines-investments-in-immunization-yield-high-returns/
Estimates social returns to R&D of 20-60% through technology spillovers, substantially exceeding private returns. Provides empirical evidence for the positive externalities of research investment, supporting public funding of basic research.
The synthetic control method provides a systematic way to choose comparison units in comparative case studies. A combination of comparison units often provides a better comparison for the unit affected by the policy intervention than any single comparison unit alone.
Appendix A: Analysis Workflow
Complete OBG Analysis Pipeline
+-------------------------------------------------------------+
| OBG ANALYSIS WORKFLOW |
+-------------------------------------------------------------+
Phase 1: DATA COLLECTION
-------------------------
1. Budget data ingestion
+-- Pull current spending by category (OMB, USASpending)
+-- Normalize categories to standard taxonomy
+-- Identify subcategories for detailed analysis
+-- Flag data quality issues
2. Cross-country spending data
+-- Pull spending data from OECD, World Bank
+-- Include all comparable countries
+-- Normalize to per-capita and % GDP
+-- Prepare for regression analysis
3. Effect estimate data
+-- Search systematic reviews and meta-analyses
+-- Extract effect sizes with standard errors
+-- Code study quality (RCT, natural experiment, etc.)
+-- Build literature database by category
Phase 2: OSL ESTIMATION
-----------------------
4. Diminishing returns modeling
+-- Fit nonlinear spending-outcome functions
+-- Identify "knee" of curve
+-- Calculate marginal returns at current spending
+-- Estimate optimal level
5. Cost-effectiveness analysis (health/life-saving)
+-- Identify interventions below CE threshold
+-- Calculate scale-up costs
+-- Sum to category OSL
+-- Document assumptions
6. Method reconciliation
+-- Compare OSL estimates across methods
+-- Weight by method reliability
+-- Produce consensus OSL estimate
+-- Flag discrepancies
Phase 3: EVIDENCE QUALITY
-------------------------
7. BIS calculation
+-- Compute quality weights per study
+-- Compute precision weights
+-- Compute recency weights
+-- Aggregate to category BIS
8. Evidence grading
+-- Assign A-F grade based on BIS
+-- Document key evidence
+-- Identify research gaps
+-- Flag high-uncertainty categories
Phase 4: GAP ANALYSIS
---------------------
9. Compute gaps
+-- Gap = OSL - Current
+-- Calculate % gap
+-- Classify as under/over/optimal
+-- Apply BIS weighting
10. Priority ranking
+-- Priority = |Gap| × BIS
+-- Rank categories
+-- Identify reallocation pairs
+-- Estimate welfare gains
Phase 5: OUTPUT GENERATION
--------------------------
11. Multi-unit reporting
+-- Natural units ($/capita, % GDP)
+-- Monetized (ROI, opportunity cost)
+-- Health units (QALYs where applicable)
+-- Composite (BIS, evidence grade)
12. Sensitivity analysis
+-- Vary key parameters
+-- Test country data subsets
+-- Report OSL ranges
+-- Identify robust conclusions
13. Documentation
+-- Generate category reports
+-- Create methodology audit trail
+-- Version control estimates
+-- Publish to dashboard/API
Appendix B: Glossary
Core Concepts
Optimal Budget Generator (OBG): The framework/methodology for generating integrated budget recommendations based on evidence of spending-outcome relationships. OBG accounts for the zero-sum nature of budget allocation and produces Optimal Spending Level (OSL) estimates for each category.
You put evidence and comparison data into the machine. The machine tells you two things: how much you should spend, and how sure you should be. Then you notice you’re spending the wrong amount.
Optimal Spending Level (OSL): The evidence-based target spending level for each category, produced by the OBG framework. \(\text{OSL}_i\) represents the optimal spending level for category \(i\). Below OSL indicates underinvestment; above OSL indicates diminishing returns.
Budget Impact Score (BIS): A 0-1 score measuring confidence in each category’s OSL estimate based on the quality and quantity of causal evidence. Higher BIS indicates more reliable OSL recommendations.
Spending Gap: The difference between current spending and the evidence-based target for each category. Positive gaps indicate underinvestment; negative gaps indicate overinvestment.
Diminishing Returns: The economic principle that marginal returns to spending decrease as spending increases. The optimal level is where marginal return equals opportunity cost.
Estimation Methods
Cost-Effectiveness Threshold: The maximum acceptable cost per QALY (or other health outcome) for including an intervention in target calculations. Typically $50K-$150K per QALY.
Dose-Response Curve: The relationship between spending level (dose) and outcome (response). Used to identify diminishing returns and estimate optimal spending levels.
Evidence Quality
Quality Weight (\(w^Q\)): Weight assigned to a study based on identification strategy. RCTs receive 1.0; cross-sectional studies receive 0.25.
Precision Weight (\(w^P\)): Weight assigned based on standard error. More precise estimates receive higher weight.
Recency Weight (\(w^R\)): Weight assigned based on publication date. More recent studies receive higher weight via exponential decay.
Evidence Grade: Letter grade (A-F) summarizing confidence in each category’s target estimate. A = strong evidence; F = insufficient evidence.
Output Concepts
Priority Score: Product of gap magnitude and BIS. Used to rank categories for reallocation priority.
Value of Information (VOI): Expected benefit of additional research on uncertain categories. High-VOI categories warrant pilot funding.
Multi-Unit Reporting: Presenting results in natural units, monetized equivalents, health units, and composite scores for interpretability.
Appendix C: Illustrative Comparison to US Budget
This appendix applies the OBG methodology to the US discretionary budget as an illustrative exercise. “Current” figures reflect approximate FY2024 budget authority. OSL estimates for pragmatic trials, vaccinations, and K-12 education are derived from the worked examples in Sections 5-7. Other OSL values integrate cross-country benchmarking and published cost-effectiveness evidence. BIS scores summarize the strength of the causal evidence.
Illustrative US Discretionary Budget vs. OSL Targets
Category
Current (\(B) | OSL (\)B)
Gap ($B)
Gap %
BIS
Inc
Hlth
Priority
Military (discretionary)
850
459
-391
-46%
0.50
−
−
195
Non-military discretionary
915
1,350
+435
+48%
0.65
++
++
283
- Pragmatic clinical trials
0.5
50
+49.5
+9,900%
0.90
++
+++
44.6
- Education
80
120
+40
+50%
0.75
+++
+
30
- Health (research)
50
100
+50
+100%
0.80
+
+++
40
- Vaccinations
8
35
+27
+338%
0.95
+
+++
26
- Basic research
45
90
+45
+100%
0.70
++
++
32
- Infrastructure
100
150
+50
+50%
0.60
++
+
30
- Early childhood
50
70
+20
+40%
0.85
+++
+
17
Agricultural subsidies
25
0
-25
-100%
0.90
−
−
23
Inc = effect on real after-tax median income growth. Hlth = effect on median healthy life years. Scale: +++ strong positive, ++ moderate, + weak, − negative.
Key findings:
Extreme underinvestment in pragmatic trials: At 9,900% below OSL with 637 (95% CI: 479-854):1 BCR, this is the single largest misallocation in the federal budget (see Section 6 for full derivation)
Overinvestment in military spending: Military spending is ~$391B (46%) above OSL estimates based on cross-country benchmarking
Underinvestment in outcomes: Vaccinations, outcome-funded R&D, and health research sit far below evidence-optimal levels
Negative-return spending: Agricultural subsidies produce negative welfare effects per the cost-effectiveness literature
Reallocation potential: The direction of reallocation runs from military and subsidies toward research, health, and education
Corresponding Author: Mike P. Sinn, Institute for Accelerated Medicine ([email protected])
Conflicts of Interest: The author declares no conflicts of interest.
Funding: This work received no external funding.
Data Availability: All data sources referenced in this paper are publicly available: OECD iLibrary (education, health spending), World Bank WDI (cross-country indicators), SIPRI Military Expenditure Database (defense spending), and CDC vaccination cost data. URLs are provided in the Data Sources section. A complete replication package including analysis code, data extraction scripts, and worked example calculations will be deposited in a public repository (GitHub/Zenodo) upon publication.
Ethics Statement: This is a methodological specification. No human subjects research was conducted.